Resolution of Generic Safety Issues: Issue 125: Davis-Besse Loss of All Feedwater Event of June 9, 1985 - Long-Term Actions (Rev. 7) ( NUREG-0933, Main Report with Supplements 1–35 )

In order to export or print, this web site requires you to enter text displayed in the distorted image on the left, which is known as Captcha, into the text field below the image.
On June 9, 1985, Davis-Besse had a partial loss of feedwater while operating at 90% power. Following a reactor trip, the loss of all feedwater occurred. The two OTSGs became dry and were ineffective as a heat sink. Consequently, the RCS pressure increased indicating a lack of heat transfer from the primary to secondary coolant systems. The PORV automatically opened and closed twice during the event upon reaching the approximate pressure setpoints; it opened a third time, but did not close for some unknown amount of time. The delayed response to close the third time aggravated the recovery of the event and allowed a rapid depressurization of the RCS.
In addition to the short-term actions identified and addressed in Issue 122, a staff report on the event was published in NUREG-1154,886 and an EDO memorandum895 identifying 29 NRR action items was issued on August 5, 1985. These items became known as long-term generic actions and, in November 1985, were forwarded by DL/NRR to DST/NRR for prioritization.940 The items were broken down into two groups: (I) Issues raised in NUREG-1154 and the EDO memorandum; and (II) Other Issues. These 29 items were evaluated separately below and were identified by the numbering system established in the DL/NRR memorandum.940
ITEM 125.I.1: AVAILABILITY OF THE SHIFT TECHNICAL ADVISOR
DESCRIPTION
Historical Background
This issue was identified as Item 5 in the EDO memorandum895 and was based on Finding 14 and Section 6.1.3 of NUREG-1154.886 During the event, neither the shift supervisor nor any of the other licensed operators requested the assistance of the shift technical advisor (STA). One reason for not doing so was the fact that the STA was not in the control room or immediately available when the event occurred, but rather was on an on-call status. (Note: An STA is allowed 10 minutes to reach the control room after being called.) Moreover, the event occurred so rapidly that it was essentially over when the STA did arrive.
STAs were first required as part of the TMI Action Plan Item I.A.1.1, "Shift Technical Advisor." The purpose of the STA was to provide readily available technical support to the plant operators. The STA's expertise was intended to aid in the mitigation of those transients and accidents which involve complex thermal-hydraulic behavior in the primary and secondary coolant systems. In summary, having the STA available was a post-TMI improvement to provide the shift supervisor with additional technical expertise, but his potential assistance and guidance was not available nor required during this event.886
Safety Significance
The safety question posed by this issue was whether the STA should be in the control room, or immediately available, to support the shift supervisor rather than being on an on-call status.
CONCLUSION
One year after the Davis-Besse incident, the staff conducted a survey to provide the Commission with the implementation results of the Policy Statement on engineering expertise on shift and reported their findings in SECY-86-231.1023 This survey found that there were only three plants that did not have "on-shift" STAs. On-shift STA means that there is an STA, or an STA-qualified SRO, in or near the control room on a shift basis during operations. The STA shift may or may not correspond to the same shift times and length as the licensed operators' shift. It further means that the STA does not work on an extended assignment period, e.g., 24 hours, during which time the STA is provided quarters to rest during a portion of his extended duty and is available on an on-call basis.
Based on the staff's findings,1023 STAs were in the control room or immediately available at the majority of operating plants. For the three plants identified with a deficiency, licensee action was being reviewed by the staff on a plant-specific basis. Thus, this item was DROPPED from further pursuit.
ITEM 125.I.2: PORV RELIABILITY
The PORV common to most PWRs (with the exception of CE 3410 Mwt and 3800 Mwt plants and ANO-2) is designed to limit system pressure if a transient recovery exceeds the capability of the pressurizer spray system. Davis-Besse has a solenoid-controlled PORV. However, many other PWRs have PORVs that are operated pneumatically (instrument air or nitrogen). Both designs have the same purpose. The PORV is designed to receive an actuation signal to open from the pressurizer pressure instrumentation at a design setpoint (typically 2425 psig) in order to prevent reactor pressure from rising and activating the code safety valves.
If a PORV is used for feed-and-bleed, it can either be: (1) set to stay open by the operator dropping the setpoint low enough such that the valve will remain open until reaching the lower setpoint for LPIS or RHR initiation; or (2) cycled open and closed many times, should there be a need for feed-and-bleed. Option 1 appeared to be the more common practice. PORVs are also used in other functions such as mitigating SGTR accidents, Ltop, or RCS venting. Its performance is required for plant protection and accident mitigation. The following is the evaluation of the four parts of this issue.
ITEM 125.I.2.A: NEED FOR A TEST PROGRAM TO ESTABLISH RELIABILITY OF THE PORV
DESCRIPTION
Historical Background
This issue was identified as Item 9c in the EDO memorandum895 and was based on Finding 13 and Section 5.2.8 of NUREG-1154.886
Safety Significance
Although the PORV can be used successfully in recovering from certain plant transients, at the time of the initial evaluation of this issue in June 1986, there had been no suitable test program established to verify its reliability.886 This issue affected all PWRs that used PORVs.
CONCLUSION
The need for improving the reliability of PORVs and block valves, in light of plant protection and accident mitigation requirements, was being addressed in the resolution of Issue 70, "PORV and Block Valve Reliability." It was believed that revising licensing criteria would be developed, if needed, to include testing requirements.896 Therefore, this issue was covered in Issue 70.
ITEM 125.I.2.B: NEED FOR PORV SURVEILLANCE TESTS TO CONFIRM OPERATIONAL READINESS
DESCRIPTION
Historical Background
This issue was identified as Item 9d in the EDO memorandum895 and was based on Finding 13 and Section 5.2.8 of NUREG-1154.886
Safety Significance
The review of the PORV maintenance and operating history revealed that the mechanical operation of the valve had not been tested and that the valve had not otherwise been operated for over 2 years and 9 months prior to the June 9, 1985 event. Therefore, it seemed that there existed a need for surveillance tests to confirm operational readiness. This issue affected all PWRs that used PORVs.
CONCLUSION
The number of times that PORV/Block Valves are used during a typical fuel cycle was expected to be reviewed in the resolution of Issue 70, "PORV and Block Valve Reliability," in order to determine if a surveillance program should be initiated to confirm operational readiness.896 Therefore, this issue was covered in Issue 70.
ITEM 125.I.2.C: NEED FOR ADDITIONAL PROTECTION AGAINST PORV FAILURE
DESCRIPTION
Historical Background
This issue was identified as Item 9e in the EDO memorandum895 and was based on Sections 5.2.8 and 6.2.1 of NUREG-1154.886
The PORV will receive an actuation signal from pressurizer pressure instrumentation at a design setpoint (typically 2425 psig) to open in order to prevent reactor pressure from activating the code safety valves. After the opened PORV has reduced the pressure sufficiently to reach its closure setpoint (typically 2375 psig), it is sent a signal to close. A simultaneous signal is also sent to the control room indicating to the operator that a close signal was sent to the PORV. After the TMI-2 accident, PORV closure can be verified by an acoustic monitor installed on the tailpipe downstream of the PORV on all PWRs. At Davis-Besse, the PORV closure is indicated by a light located on a wall several feet from the operator's control panel. This was available to the operator at Davis-Besse to verify whether the PORV was closed but was not looked at. Additionally, there was the SPDS, also a post-TMI improvement, that displays a summary of the most safety significant plant status information on a TV screen. Both channels were inoperable prior to the event.886 This left the operators with only the pressurizer pressure indicator as a source of determining if the PORV was open or closed. Since the indicator appeared steady, the operator assumed that the PORV had closed, but closed the block valve as a precautionary measure. In actuality, however, the PORV had not closed until some time later into the event.
Safety Significance
At the time of the initial evaluation of this issue in June 1986, there had been several stuck-open PORVs documented due to a variety of malfunctions, some of which were identified to be mechanical failure, broken solenoid linkage, inoperability due to corrosion buildup, and sticking caused by foreign material.886 As a precaution, the PORV block valve can be closed to ensure no LOCA, but this can only be achieved if the operator closes the block valve by remote-manual operation from the control room. In the Davis-Besse event, the operator closed the block valve to prevent a further decrease in pressure and loss of primary coolant through the PORV when it did not reseat.
Possible Solution
Knowing that a stuck-open PORV may result in a potentially dangerous scenario (i.e., LOCA), this issue addressed the concern of whether there was a need for an automatic block valve closure in plants that have PORVs.
Considering available control room indicators such as an acoustic monitor, a reliable SPDS, and the operator's acute sensitivity to the PORV's status because of historical events such as TMI-2 and Davis-Besse, another redundant feature (i.e., automating the block valve) would not necessarily result in a significant decrease in core-melt frequency. The acoustic monitor was available to the operator at Davis-Besse; the SPDS was not. However, there was an NRC requirement for the installation of "a concise display of critical plant variables to the control room operators to aid them in rapidly and reliably determining the safety status of the plant."376
Additionally, there was a DHFT/NRR program underway "to determine the need for and, if necessary, the scope of the NRC's SPDS post-implementation reviews."900 The information obtained was expected to "allow an assessment of how well the SPDS objectives are being met and provide the basis for an NRC regulatory position on SPDS post-implementation reviews. Following completion of this program DHFT/NRR will, if necessary, work with industry to develop appropriate standards for SPDS availability."900
The staff performed SERs897, 898, 899 on the three vendor group responses (CE, B&W, W) to TMI Action Plan Item II.K.3(2), "Report on Overall Safety Effect of Power-Operated Relief Valve (PORV) Isolation System." The SERs included an estimate of core-melt frequency due to a stuck- open PORV-induced SBLOCA. The calculations were based on PORV operating data from April 1, 1980, to March 31, 1983, and it was concluded that post-TMI actions, such as lowering the setpoint of the high pressure reactor trip and raising the setpoint of the PORV opening, eliminating the turbine runback feature, and improving operator capability, decreased the challenge to the PORV and the probability of a SBLOCA-PORV sufficiently so as not to warrant a requirement for automatic block valve closure. The Davis-Besse event could be viewed as another "data point" to be considered in this determination. However, upon consideration of the occurrence of a PORV actuation and the conservative estimates made in the staff's SERs,897, 898, 899 it was concluded that the SBLOCA-PORV frequency would still remain within the range of the SBLOCA frequencies given in WASH-140016 (10-2 to 10-4/RY). The opening of the PORV resulted from a loss of all feedwater to the steam generators and was regarded as a legitimate response and fulfillment of the real purpose for incorporating a PORV into the design. Therefore, the Davis-Besse event did not change the statistics for necessary challenge to the PORV. Consequently, the staff's SERs,897, 898, 899 which concluded that block valve automation was unnecessary, were unaffected.
It was also clear that the automation of the block valve could reduce the initiator (SBLOCA-PORV) frequency, but not necessarily the net core-melt frequency, since it had the potential for spurious actuation (e.g., spurious electrical signal sensed by the block valve could force it closed during a transient requiring use of the PORV) which would increase core-melt frequency.
The occurrence at Davis-Besse was the result of an initiator already considered in the SERs, i.e., the failure of the AFW system. It was an occurrence that would have resulted in no other outcome if an automatic block valve had been available, because the operator closed the block valve himself as a result of his sensitivity to the PORV from post-TMI training.
CONCLUSION
In light of the control room indications available to the operators and the results of the staff SERs897, 898, 899 in which it was concluded that an automatic PORV isolation system was not necessary, the safety concerns of this issue were resolved. Thus, this issue was DROPPED from further pursuit as a new and separate issue.
ITEM 125.I.2.D: CAPABILITY OF THE PORV TO SUPPORT FEED-AND-BLEED
DESCRIPTION
Historical Background
This issue was identified in the EDO memorandum895 and was also raised at an ACRS Subcommittee meeting on Emergency Core Cooling Systems held on July 31, 1985.
Safety Significance
Upon loss of the main and auxiliary feedwater systems, the feedwater flow to the steam generators is insufficient to maintain level. As the level of water in the steam generators decreases, the average temperature of the RCS increases because of the reduced heat transfer from the primary to the secondary coolant systems. When all steam generators are "dry," the plant emergency procedure requires the initiation of makeup/high pressure injection (MU/HPI) cooling of the primary system.886 This method of decay heat removal is known as "feed-and-bleed" or "bleed-and-feed" depending on the HPI capability of the injection pumps and system design. When this method is initiated, the PORV and high point vents on the RCS, specifically the pressurizer, are locked open breaching one of the plant's radiological barriers and releasing radioactive coolant inside the containment building.886 MU/HPI is often considered a drastic action because of the radioactive contamination of the containment. Nevertheless, MU/HPI cooling provides a diverse method of core cooling if the main and auxiliary feedwater systems should fail.
This issue was based on an ACRS concern that the PORVs were not qualified for the "hostile" environment in which they were placed when used for feed-and-bleed operation. There were several reasons for this concern. PORVs are usually called upon to respond when all other methods of removing decay heat are not available. The temperature, pressure, and moisture conditions of the containment environment can create a differential thermal expansion of the valve disc and body and may cause the PORV to stick,886 failing open or closed, or the PORV can close shortly after beginning feed-and-bleed because of short circuits.
CONCLUSION
At the time of the initial evaluation of this issue in June 1986, the staff was investigating alternative means of decay heat removal in PWR plants using existing equipment or devising new methods in the resolution of Issue A-45, "Shutdown Decay Heat Removal Requirements." The use of the "feed-and-bleed" procedure was included in this program as well as the need for environmental qualification of the PORV for this method of emergency decay heat removal. Therefore, this issue was covered in Issue A-45.896
ITEM 125.I.3: SPDS AVAILABILITY
DESCRIPTION
Historical Background
This issue was identified as Item 10c in the EDO memorandum895 and in a September 19, 1985, DHFS/NRR memorandum.900 The issue addressed the concern as to whether NRC requirements should be revised regarding SPDS availability.
Investigations subsequent to the TMI-2 accident indicated a need for improving how information is provided to control room operators both during normal and abnormal conditions. TMI Action Plan Item I.D.2, "Safety Parameter Display System (SPDS)," required that licensees install a system to continuously display information from which the plant safety status can be readily assessed. Generic Letter 82-33376 (Supplement 1 to NUREG-0737) mandated that licensees install an SPDS. Licensee implementation of Item I.D.2 was reviewed and tracked as MPA F-09. The staff requirement imposed on the licensees did not contain specific reliability or availability requirements for the SPDS.
The schedule for operating reactors to meet the requirements of Generic Letter 82-33376 was proposed to the Commission in SECY-83-4841037 and formalized in confirmatory orders or licensing conditions. At the time of the initial evaluation of this issue in May 1988, some plants had incorporated the SPDS implementation into their living schedules; however, other plants had not yet installed the SPDS. Staff actions on MPA F-09 were ongoing to perform NRC post-implementation audits to determine the status of the plants that had installed the SPDS and to modify the schedule for those that had not.
A 1985 survey of six operating plants indicated that two of the plants did not have an operational SPDS although they indicated that they met the requirements of Item I.D.2 (MPA F-09). Three plants were identified as having SPDS availability problems (less than desirable availability). At some of the plants, the SPDS presented potentially misleading information, while others suffered from poor operator acceptance or lack of management support.
As of May 1988, post-implementation verification inspections indicated that, of the 37 plants that claimed to have completed the implementation of MPA F-09, less than satisfactorily met all the SPDS requirements and were accepted by the NRC as operational. The 55 plants that claimed to have completed the implementation of MPA F-09 had not yet been inspected. Fifteen plants had not yet declared the implementation of the SPDS to be completed and three plants had not yet scheduled the implementation of the SPDS.
Safety Significance
Events such as those that occurred at TMI-2, Davis-Besse, Oconee, Rancho Seco, and others may have been less severe if an operable SPDS had been available to the operators. For the Davis-Besse event, "...(t)he inoperability of the SPDS and lack of adequate indications of steam generator conditions contributed to the control room operators not knowing that the steam generators were dry, which resulted in their failure to follow the appropriate procedures."886
The requirements of MPA F-09 indicated that each operating reactor should have an SPDS that would display to operating personnel a minimum set of parameters, in order to determine the safety status of the plant during normal and abnormal conditions. The SPDS should provide enough information to alert the control room operators, who should then verify the information presented by the SPDS before taking any action to avoid a degraded core event. The parameters should provide, as a minimum, information about the following: reactivity control; reactor core cooling and primary system heat removal; reactor coolant system integrity; radioactivity control; and containment conditions.
The primary purpose of an available SPDS would be to display a full range of these important plant parameters in order to aid the control room personnel in determining the safety status of the plant during abnormal and emergency conditions, and in assessing where abnormal conditions warrant corrective operator action to avoid a degraded core event. It was assumed that operators needed all available parameter information for their decision-making in avoiding a degraded core event and that a properly functioning SPDS would result in a lower frequency of control room operator errors and a corresponding reduction in core-melt frequency.
Possible Solution
It was assumed that all plants had an SPDS or were scheduled to have one installed. It was conservatively assumed that, at 75% of the plants, the SPDS was not operational (i.e., not available for use) and that, at the remaining 25%, the SPDS was operational but, due to errors in design and/or construction, may provide misleading information to plant operators. It was assumed that improvements in design and hardware charges, as well as improved maintenance and test procedures, would be required to assure the availability of a properly functioning SPDS at all operating plants.
PRIORITY DETERMINATION
Assumptions
During the prioritization of a selected group of MPAs in October 1984, MPA F-09 was analyzed by PNL.1039 The PNL analysis evaluated the risk reduction benefit obtained by the design, installation, and maintenance of an operating SPDS. The PNL cost analysis evaluated the NRC and licensee costs expected for the design, procurement, installation, and operation of the SPDS over the expected plant life.
The PNL risk analysis for MPA F-09 was based on NUREG/CR-32461040 and the IREP risk assessment for ANO-1.366 NUREG/CR-32461040 dealt with the risk reduction related to three improvements in the control room: (1) installation of a SPDS; (2) installation of a margin to saturation annunciator; and (3) increased control room staffing. Since the risk reduction associated with the availability of an operable SPDS was the concern of this issue, the analysis of NUREG/CR-32461040 was used and modified to separate out the effect on core-melt frequency due to having an operable SPDS. The effect on core-melt frequency due to the SPDS was then carried through the appropriate event sequences and minimal cut sets in the IREP risk assessment to determine the potential level of public risk afforded by an operable SPDS.
It was conservatively assumed that 75% of all plants had an SPDS which was installed but not operationally available, and 25% of the plants had an operational SPDS which provided misleading information. It was assumed that resolution of this issue would ensure that all plants had a properly operating SPDS available and continuously in use.
Frequency Estimate
The level of risk presented by having the SPDS installed but not available was the same as not having an SPDS. Therefore, the PNL risk analysis for MPA F-09 was used to estimate the risk reduction obtainable by resolving the issue (i.e., making the installed SPDS continuously available and correcting any existing design or operational deficiencies) for the 75% population of the plants. For the remaining 25% of the plants, which were assumed to have an SPDS that might mislead the control room operators, the following were assumed: a two order of magnitude increase in the frequency of failure to notice relevant annunciators; failure to properly diagnose the event; errors of omission in following emergency procedures; errors of commission in establishing HPI cooling and recovery factors for operator errors. The PNL analysis using these modified probabilities for specific events in the cut set analysis were repeated.
The population of plants (75%) assumed to have an installed but unavailable SPDS was estimated to consist of 60 PWRs and 27 BWRs with remaining lives of 32 years and 30.8 years, respectively. The event tree (HPI-PUMP-CM), which depicted failure of HPI, was assumed to be affected by the addition of an SPDS. This event tree included failure of adequate core cooling as the initiating event and individual probabilities for the failure to notice relevant annunciators, failure to properly diagnose the event, errors of omission in following emergency procedures, errors of commission in establishing HPI cooling, and recovery factors for various operator errors. From NUREG/CR-3246,1040 the base case probability for the HPI-PUMP-CM event was 2.18 x 10-3.
In the SNL study of control room improvements (NUREG/CR-3246),1040 the addition of an SPDS in the control room was assumed to reduce the probability of the operator failing to recognize the loss of margin-to-saturation annunciators from 1.3 x 10-2 to 10-4 (an improvement in the recovery factor) and provide a capability to detect omission of steps in the emergency procedure (an additional path on the event tree with a failure probability of 10-4). The adjusted case probability of the HPI-PUMP-CM event was determined to be 4.4 x 10-4.
In the MPA F-09 analysis,1039 PNL calculated the change in core-melt frequency using the ANO-1 IREP analysis with the base case and adjusted case frequencies for the HPI-PUMP-CM event. The calculated change in core-melt frequency represented the addition of an SPDS for each dominant sequence of events in which the affected event (HPI-PUMP-CM) appeared. For the purpose of determining the potential risk reduction for resolution of this issue for the 75% population (i.e., improving availability of existing SPDS), this was the same as the MPA F-09 analysis with and without the SPDS, as determined by PNL. The affected base case core-melt frequency (without SPDS) was calculated to be 1.04 x 10-6/RY and the adjusted case affected core-melt frequency (with SPDS) was calculated to be 2.09 x 10-7/RY. The core-melt frequency reduction (8.3 x 10-7/RY) determined by PNL was assumed to be typical of all PWRs.1039 When the change in core-melt frequency for PWRs was multiplied by the appropriate dose conversion factors, the number of affected PWRs (60) and their average remaining life (32 years), a risk reduction of 3,802 man-rem was estimated. The estimates of core-melt frequency and risk reduction for BWR plants were determined by proportioning the total core-melt frequency and total public risk from the ANO-1 IREP and Grand Gulf-1 RSSMAP risk assessments and multiplying the ratio to the PWR core-melt frequency and risk reduction estimates determined above. Core-melt frequency and total risk reduction estimates, due to the addition of an SPDS, of 6.1 x 10-7/RY and 4,116 man-rem, respectively, were thus calculated for 27 affected BWRs for their average remaining life (30.8 years). Thus, summing the BWR and PWR estimates, a total public risk reduction of 7,918 man-rem was calculated for resolving this issue at the 75% population of plants assumed to have poor availability.
It was determined that the remaining 25% population of plants, which were assumed to have an available SPDS capable of misleading the plant operators during abnormal operations, consisted of 20 PWRs and 10 BWRs with remaining lives of 32 years and 30.8 years, respectively. Due to the detrimental effect a faulty SPDS can have on a situation in the control room, the probability of certain parameters was increased by two orders of magnitude from the case where no SPDS was considered. These parameters were as follows: failure to notice relevant annunciators; misdiagnosis; and errors of omission in the respective steps of the emergency procedures. Repeating the PNL analysis1039 of using the higher operator error values, a PWR HPI-PUMP-CM probability of 1.75 x 10-2 was calculated and, using the ANO-1 minimal cut sets, a PWR core-melt frequency of 8.76 x 10-6 /RY was calculated. Using the above ratioing technique, a BWR core-melt frequency of 6.6 x 10-6/RY was estimated. Subtracting the base case (good SPDS continually available) estimated core-melt frequencies (2.09 x 10-7/RY for PWRs and 1.55 x 10-7/RY for BWRs) from the adjusted case values for the 25% population of plants with "faulty" SPDS produced a core-melt frequency reduction of 8.55 x 10-6/RY for PWRs and 6.44 x 10-6/RY for BWRs.
Consequence Estimate
Multiplying the core-melt frequency by the appropriate dose conversion factors, number of affected plants, and their respective average remaining lives, produced a potential public risk reduction of 13,376 man-rem for the PWRs and 16,301 man-rem for the BWRs of the remaining 25% population of plants. Summing the PWR and BWR estimated risk reductions for the 25% population of plants assumed to have a faulty SPDS, the estimated total risk reduction for this fraction of the total population of plants was (13,376 + 16,031) man-rem or 29,407 man-rem.
Since resolution of the issue was assumed to both greatly improve availability of the SPDS and correct the deficiencies in those SPDS that may be "faulty," the total risk reduction estimated for the issue was (7,918 + 29,407) man-rem or 37,325 man-rem.
Cost Estimate
Industry Cost: For the MPA F-09 cost analysis,1039 PNL consulted industry vendors who supplied SPDS systems. PNL estimated an industry SPDS implementation cost of $3M/plant equally divided between vendor procurement costs and licensee design and installation costs. For the purpose of this analysis, it was assumed that modifications to an existing SPDS to correct either severe availability problems or design deficiencies could not be accomplished for less than 10% of the original design, procurement, and installation cost. Therefore, the estimated total industry implementation cost was $35.1M.
In the MPA F-09 analysis,1039 PNL estimated 2 man-weeks/year/plant to operate, inspect, and maintain the SPDS. For this analysis, it was estimated that one additional man-week of industry maintenance and surveillance effort would be required each year to maintain and demonstrate adequate SPDS availability. A total present worth cost of $8.4M was estimated for operation and maintenance of an improved SPDS at all affected plants. Thus, the total industry cost was $43.5M.
NRC Cost: It was estimated that 12 man-weeks/plant would be needed to review the SAR on a modified SPDS, prepare an SER supplement, inspect the SPDS after its modification, and review and issue revised TS for the operation and surveillance of the SPDS. This was estimated to cost $270,000/plant or $3.2M total cost. In addition, one man-week/plant/year would be required to review and monitor each licensee's improved (expanded) maintenance and surveillance program. At $2,270/man-week, a present worth cost of $8.4M for operation and maintenance review was estimated. Thus, the total estimated cost was $11.6M.
Total Cost: The total industry and NRC cost associated with the possible solution was estimated to be $(43.5 + 11.6)M or $55.1M.
Value/Impact Assessment
Based on an estimated public risk reduction of 37,325 man-rem and a cost of $55.1M for a possible solution, the value/impact was given by:
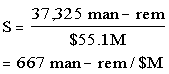
Other Considerations
Control room instrumentation systems have been designed in compliance with GDC 13 and 19 of Appendix A to 10 CFR 50 and, as such, are required to provide the operators with the information necessary for safe reactor operation under normal, transient, and accident conditions. The SPDS is used in addition to the control room instrumentation system to aid and augment the control room instrumentation system. Supplement 1376 to NUREG-0737 required that licensees develop procedures which describe the timely and correct safety status assessment when the SPDS is and is not available. It also required that operators be trained to respond to accident conditions both with and without the SPDS available. The SPDS is therefore viewed as enhancing the operator's perception and understanding of plant status under normal and abnormal conditions, but the SPDS is not essential to proper and timely diagnosis and effective recovery from abnormal events. The normal plant instrumentation system is a redundant safety grade system. The SPDS addition provides a diverse and improved diagnostic system but is redundant to the plant instrumentation system which, by the nature of its design requirements, is also redundant.
Since all modifications, maintenance, and surveillance would be performed in the control room complex, there was no potential ORE expected. The SPDS is a redundant (but enhanced) back-up system for the redundant, safety-grade control room plant instrumentation system. Intuitively, one would, therefore, not suspect that the risk sensitivity to SPDS availability (7,918 man-rem) would be so great as to warrant improvements in SPDS availability regardless of cost. In addition, in the risk analysis it was conservatively assumed that poor availability meant 100% unavailability of the SPDS for the population (75%) of plants assumed to suffer from less than desired availability.
If the availability concern were considered separately, i.e., the total population of plants (100%) was assumed to have an SPDS which is unavailable, the maximum public risk contribution (calculated conservatively) would be about 10,400 man-rem. In this instance, a medium priority would be warranted unless the total cost/plant to increase availability significance was less than $30,000, which seemed highly unlikely.
If the smaller population of plants (30) assumed to have "faulty" SPDS (i.e., one which may mislead control room operators during their response to a transient or LOCA) was considered separately, a much larger potential public risk contribution (29,407 man-rem) would result. This averaged out to slightly less than 1,000 man-rem/reactor for this smaller population. A medium priority was appropriate for this concern unless the cost to modify the SPDS equipment to correct the design faults was less than approximately $300,000/plant (10% of the SPDS original cost). It was believed that re-analysis of design and equipment replacement or modification for less than 10% of the original procurement cost was unlikely.
Conversely, recognizing that the foregoing treatment of the case of the operator being misled was conservative, if it were assumed that there was no chance of the SPDS misleading the operator (i.e., no public risk impact), the priority assignment would be based solely on the risk potential associated with the availability concern and the issue would still warrant a medium priority assignment. Therefore, considering both the overall risk and cost calculations and the separate effects for the two separate concerns identified by the Davis-Besse event (i.e., availability and design adequacy) and the limited surveys of SPDS status at operating plants, the potential risk reduction and the value/impact ratio indicated a medium priority (see Appendix C).
CONCLUSION
Generic Letter No. 82-33376 transmitted Supplement 1 to NUREG-073798 to clarify the TMI action items related to emergency response capability, including Item I.D.2, "Safety Parameter Display System." The staff evaluated licensee/applicant implementation of the SPDS requirements at 57 units and found that a large percentage of designs did not satisfy requirements identified in Supplement 1 to NUREG-0737. Generic Letter 89-061205 (enclosing NUREG-13421206) was issued to inform licensees of the staff's findings to aid in implementing SPDS requirements. Based on the staff's efforts in pursuing the implementation of TMI Action Plan Item I.D.2, this issue was RESOLVED and no new requirements were established.
ITEM 125.I.4: PLANT-SPECIFIC SIMULATOR
DESCRIPTION
Historical Background
This issue was identified as Item 10c in the EDO memorandum895 and was based on Findings 10 and 17 and Sections 6.1.1 and 6.1.2 of NUREG-1154.886 Following the Davis-Besse reactor trip, the operator manually initiated actuation of the Steam and Feedwater Rupture Control System (SFRCS) in anticipation of the automatic initiation of the SFRCS; however, the operator pushed the wrong buttons. This was the first time he had manually actuated the SFRCS and he had not received specialized classroom or simulator training on correctly initiating the SFRCS. The buttons pushed by the operator activated the SFRCS on low pressure for each steam generator instead of low level. By manually actuating the SFRCS on low pressure, the SFRCS was signalled that both steam generators had experienced a steamline break or leak and the system responded, as designed, to isolate both steam generators. Thus, the operator's anticipatory action defeated the safety function of the AFW system. The error was corrected within approximately one minute by resetting the SFRCS and, therefore, had no significant bearing on the outcome of the event. However, the lack of plant-specific simulator training was noted by the investigating team.
This event, however, was not the first event that indicated the need for plant-specific simulator training. The TMI-2 event on March 28, 1979, clearly focused industry and NRC attention on the need for better human engineering in control room design and for plant-specific simulator training. TMI Action Plan Task I.A48 contained a series of requirements related to simulator uses and developments addressing short-term and long-term actions centered on simulator training. Some of the Task I.A items48 were subsequently integrated into the Human Factors Program Plan (HFPP)651 which was developed in response to NUREG-0885210 and Section 306 of the Nuclear Waste Policy Act of 1982 (PL 97-425). In this regard, PL 97-425 required NRC to establish simulator training requirements for plant-licensed operators and operator requalification examinations. Item I.A.4.1, "Initial Simulator Improvement," was completed and Item I.A.4.2(4), "Long-Term Training Simulator Upgrade," was to be completed upon publication of 10 CFR 55 and related NRC guidance on the evaluation of simulation facilities.
Safety Significance
A plant-specific simulator would improve operator actions and timing in response to plant transients and accidents. Thus, plant damage and possible core-melt accidents could be significantly reduced. This issue affected all licensed nuclear power plants.
Possible Solution
The use of plant-specific simulators was being addressed in the proposed rulemaking957 amendments to 10 CFR 55 [TMI Action Plan Item I.A.4.2(4)]. This action was expected to codify requirements that include the use of nuclear power plant simulators in initial and requalification examinations. The proposed rulemaking included three choices for plants that were not the reference plant for a simulator: (1) acquire a plant-referenced simulator that met the intent of Regulatory Guide 1.149439; (2) use a simulator that conformed to Regulatory Guide 1.149439 and had been demonstrated to be suitable; or (3) substitute any device or combination of devices that met the requirements of 10 CFR 55.45(b) and would be approved by the NRC.
CONCLUSION
Based on the above, the resolution of the need and use of plant-specific simulators was being addressed as part of the proposed rulemaking amending 10 CFR 55 under Item I.A.4.2(4). Thus, Issue 125.I.4 was DROPPED from further pursuit as a new and separate issue.
ITEM 125.I.5: SAFETY SYSTEMS TESTED IN ALL CONDITIONS REQUIRED BY DBA
DESCRIPTION
Historical Background
The issue was based on Finding 15 of the IIT report886 which stated: "Thorough integrated system testing under various system configurations and plant conditions as near as practical to those for which the system is required to function during an accident is essential for timely detection and correction of common mode design deficiencies."
Safety Significance
Section 7 of the IIT report attributed the key safety significance of the Davis-Besse event to the fact that multiple equipment failures occurred, initiating a transient beyond the design basis of the plant. According to the IIT report, each of the following conditions contained a mix of operating errors, maintenance errors, and design errors that, without corrective operator actions, would have defeated operation of the safety-related AFW system. These were as follows:
(1) Operator Error in SFRCS Actuation on Low Pressure
Following the loss of main feedwater during the event, the operator, in anticipation of SFRCS actuation on low steam generator water level, inadvertently pushed the wrong two buttons which activated the SFRCS on low steam generator pressure instead of low steam generator water level. By manually actuating the SFRCS on low pressure, the SFRCS was signaled that both steam generators had experienced a steamline break or leak. Thus, the operator's anticipatory action (human error) defeated the safety function of the AFW system. The shift supervisor quickly determined that the AFW system valves were improperly aligned and reset the SFRCS (tripped it on low level) and corrected the operator's error about a minute after it occurred.
(2) Failure of the AFW System Containment Isolation Valves to Reopen after Their Inadvertent Closure
After the shift supervisor had reset the SFRCS, both AFW containment isolation valves could not be reopened from the control room either automatically or by manually operating the SFRCS reset and block following the inadvertent closure. This caused the complete loss of the AFW safety function by blocking flow of the AFW to both steam generators. The probable root cause of the AFW containment isolation valves inability to reopen was attributed to improperly adjusted torque switch settings on the valve actuator. Thus, power to the actuator motor was cut off before the valves could open against the high differential pressure across the valves. The safety function for the AFW isolation valves had been incorrectly specified as only to close, not to open or reopen. Thus, the AFW and SFRCS design reviews revealed that neither system met the design single failure criterion with respect to opening an AFW containment isolation valve to feed an intact steam generator. The containment isolation valves were opened by dispatching equipment operators to the rooms containing the valves where they reopened the valves in about 3.5 minutes.
(3) Overspeed Tripping of the AFW Pumps
The operator, after returning to the AFW station, expected the AFW to be actuated and providing the needed feedwater to the steam generators. Instead, he saw the No. 1 AFW pump, followed by the No. 2 AFW pump, trip on overspeed. Had both systems (the AFWS and the SFRCS) operated properly, the operators mistake in pushing the wrong buttons would have had no significant consequences. A review of the AFW design indicated that the AFW steam crossover lines (i.e., those associated with the opposite steam generator for each AFW turbine and steam admission valves) have long horizontal runs where saturated hot water could accumulate. Thus, the fluid entering the AFW turbines initially was a mixture of water and steam, but soon was entirely steam. The turbine governors could not respond quickly enough to the changing energy content of the fluid being provided and the turbines tripped on overspeed. However, the turbine overspeed trips were cleared by opening the trip throttle valves located in the AFW pump rooms.
The Davis-Besse event demonstrated the susceptibility of redundant equipment to various common mode failures and the importance of "defense-in-depth" and operator training to ensure safety. The value of redundancy, diversity, and prompt and effective operator action in accomplishing key safety functions was particularly evident from the Davis-Besse event.
Possible Solutions
In accordance with Finding 15, an essential solution for timely detection and correction of common mode design deficiencies was to conduct thorough integrated system testing under various system configurations and plant conditions (as near as practical) for which the systems are required (designed) to function during an accident.
To develop a Finding 15 test program, tests would have to be devised to simulate various plant conditions, equipment alignments, and plant responses (possible functional and spatial coupling mechanisms) to postulated abnormal and accident situations. To facilitate identification of unforeseen common mode design deficiencies (CMDD-triggers) in equipment or systems, a judicious selection of induced equipment malfunctions and/or operator errors may need to be modeled into the tests. Because it is virtually impossible to model or test for all possible off-normal conditions, the problem of devising such tests are similar to the problems encountered by the staff during development of the Design Basis Events (DBEs) used to license plants. In establishing the DBEs, the staff recognized that it was impractical, if not impossible, to anticipate (postulate) all possible transients, abnormal operations, accident conditions, equipment malfunctions, and operator errors that may occur during the life of a plant. To overcome these limitations and to provide adequate assurance that the plants could operate safely, the staff included DBEs in the SRP11 in an attempt to bound the unforeseen events that might occur.
For the purposes of estimating the potential scope of this issue, and due to the similarities between the objectives stated in Finding 15 and the licensing DBEs, it was assumed that a thorough integrated system test program might, as near as practical, attempt to simulate the postulated licensing DBEs described in SRP11 Section 15. Because of the complexities involved in attempting to simulate all the DBE conditions, the possibilities of inducing some fuel failures under the more severe DBEs, and the physical limitations of actually conducting tests to model many of the DBEs, it did not appear practical or realistic to conduct a test program under all DBE conditions.
It was assumed that the closest approach to the Finding 15 recommendation (to conduct a thorough integrated systems/plant test program) would be a test program similar to the Rancho Seco restart test program. However, because plant-specific test programs could vary significantly, the potential range in costs of each plant-specific test program, as discussed herein, reflected a wide range of potential costs that could be dominated by possible extended refueling outages that could result from implementing the test programs.
The Rancho Seco test program included component testing, systems integrated functional testing, and plant integrated functional testing. These tests included logic tests of systems interlocks, trips, permissives, and verifications of the annunciators. Normal operations testing would include cold and hot shutdown conditions, with some testing performed during the power ascension phase. During the normal operations testing, verification of systems functions would be conducted. Many of these tests were already being performed during In-Service Testing (IST) or during normal refueling outages, but improved methods and procedures could be needed and could affect on-line power production. The integrated Rancho Seco systems/plant testing phase included, where practical, emergency/off-normal operations such as the loss of the Integrated Control System (ICS), Non Nuclear Instrumentation (NNI), offsite power, and ECCS testing.
Based on the Rancho Seco test flow diagram, many of the latter tests, such as cold functional Emergency Feedwater Integrated Control (EFIC), Safety Feature Actuation Systems (SFAS), diesels, and condenser vacuum tests, could be performed in parallel over approximately 3.5 months. However, the loss of offsite power, plant heatup, hot shutdown, and power ascension testing would be conducted in series over an additional 3.5 months. In summary, it was estimated that the Rancho Seco systems/plant testing phase would require approximately 7 months to complete and included the following major integrated test matrix:
(1) Loss of offsite power
(2) Integrated SFAS
(3) Loss of instrument air
(4) EFIC functional
(5) Loss of ICS/NNI power
(6) Condenser vacuum
(7) Integrated leak test
(8) Flow balance
(9) Cold systems functional
(10) Hot systems functional
(11) Power systems functional
(12) Reactor trip
(13) ICS tuning
It was noted, however, that the integrated systems/plant test matrix did not include all the DBEs. Nevertheless, the Rancho Seco test program should provide insight into the potential magnitude and scope of an integrated systems/plant testing program, under various systems configurations and plant conditions, that approached the Finding 15 recommendation. However, to meet the Finding 15 objective of detecting unforeseen CMDDs, it may be necessary to devise and include by judicious selections, off-normal equipment malfunctions and operator errors to provide the coupling mechanism(s) that force detection of the unforeseen CMDDs.
Because of the infinite combinations of possible equipment or system malfunctions and operator errors, the likelihood of success in detecting unforeseen CMDDs by a designed test program, using limited and designed combinations and designed procedures, would likely be plant-specific. The chance of success could be severely limited by the imagination used in devising the tests and in selecting appropriate coupling mechanisms that will force detection of the unforeseen CMDDs.
The potential complexities in developing a thorough integrated systems/plant test program, especially one designed to detect unforeseen CMDDs, were enormous and were not considered a simple engineering task nor a series of simple tests. Nevertheless, it was assumed that the integrated systems/plant testing phase could be reduced by a factor of ten to 0.7 months (3 weeks) beyond the normal refueling outage. Thus, outage extensions that may range from 3 weeks to 7 months should bound all or most of any plant-specific variabilities in outage extension costs that may be attributed to the test programs.
PRIORITY DETERMINATION
The objective of the Finding 15 integrated systems/plant test program was to detect and correct unforeseen (unknown) CMDDs that may surface as a result of off-normal or accident conditions during plant operations. Since no specific event or safety system was identified in Finding 15, the problem involved virtually every safety system in a plant. Because all plants exhibit various degrees of complexities in their safety systems and various susceptibilities to common mode failures, any attempt to identify plant/system hazards for all possible common mode failures (especially unknown common mode failures) either singly or in combinations is impossible. Therefore, to a large extent, plant-specific hazards from all common mode failures may vary considerably from plant to plant. These conditions also apply to the unforeseen CMDDs (a subset of common mode failures) which are considered in this analysis.
At the time of the initial evaluation of this issue in November 1988, the methods for systematically evaluating equipment or system failures involved the use of operational data. This data provided equipment and system unavailabilities to estimate the probabilities of dominant accident sequences that may lead to core damage (considered herein as a core-melt condition). The operational data on equipment and system unavailabilities generally included common mode or common cause events that are not specifically identified in the systemic event tree of the accident sequences. A fault tree model of the equipment or system would contain more specific information on common mode or common cause initiators that affect the specific equipment or system unavailabilities.
The items that were to be addressed in this analysis were: (1) the likelihood of unforeseen CMDDs that have not yet occurred; (2) the chance of success of detecting and correcting unforeseen CMDDs; (3) the likelihood of core-melt from unforeseen CMDDs; (4) the estimated risk reduction potential associated with detecting and correcting the unforeseen CMMDs; and (5) the estimated cost range of implementing possible thorough integrated systems/plant test programs discussed earlier.
Frequency Estimate of Unforeseen CMDDs: To estimate the frequency of unforeseen common mode failures, information was obtained on the frequency of previous unforeseen common mode failures that had actually surfaced in operating plants. The information used in this analysis was based on results of research conducted by EPRI.745 The data gathered in the EPRI report was limited to a select group of components covering approximately 400 to 600 RY of experience; 2654 events were evaluated in the EPRI report and each event involved at least one component in an actual or potential state of being failed or functionally unavailable. Of the 2,654 events, 2,232 were classified as independent events and 422 were classified as dependent events. Of the dependent events, 113 were classified as common cause events and 68 were classified as actual common cause events because they involved two or more actual failed or functionally unavailable states.
The method used in the EPRI report to quantify equipment common cause failure values was the Basic Parameter Method (BPM). The overall methods included in the EPRI report involved essentially an extension of the Beta Factor Method and the Multiple Greek Letter Method. These methods provided means for estimating the conditional probabilities from common cause events involving two, three, or more units, given that a specific component failure occurred.
The generic beta basic parameter values calculated by EPRI reflected the compilation of all the reviewed data on common mode failures for the components and systems listed below. In accordance with NUREG-1150,1081 these EPRI values reflected a 95% upper bound of a log normal distribution with an error factor of three. The mean values (taken from NUREG-1150) were listed and were used in this analysis to estimate the potential generic contribution to core-melt frequency from common cause failures. The upper bound beta basic parameter values were used in the NUREG-11501081 sensitivity study to bound the potential effects of common cause failures (CCFs) on severe core damage.
The EPRI report included the results of extensive data reductions, root-cause determinations, and evaluations of 2,654 events that included independent and dependent events over 400 to 600 RY of operation. Because plant-specific data were scarce even for single failure probabilities (and even more scarce for dependent failures), use of the EPRI industry-wide data provided a more comprehensive generic data base than the Davis-Bessie event that involved multiple component/systems failures.
Generic Beta Values
| Component | Upper Bound Values | Mean Values |
|---|---|---|
| Reactor Trip Breakers | 0.19 | 0.079 |
| Diesel Generators | 0.05 | 0.021 |
| MOVs | 0.08 | 0.033 |
| PWR SRVs | 0.07 | 0.029 |
| BWR SRVs | 0.22 | 0.092 |
| Batteries | 0.10 | 0.040 |
| High Head Pumps | 0.17 | 0.071 |
| RHR Pumps | 0.11 | 0.046 |
| Containment Spray Pumps | 0.05 | 0.021 |
| AFW Pumps | 0.03 | 0.013 |
| Service Water Pumps | 0.03 | 0.013 |
| Average of All Beta BPM Values | 0.10 | 0.042 |
In addition to the above beta BPM values, the EPRI report grouped the failure events into two classes. The Class I failures included all the generic common cause events. Both classes were classified as having eight generally related causes (triggers). Although the Class I events occurred 10 times less frequently than the Class II events, the relative frequencies of the cause (trigger) groups suggested that the causes of dependent events in general, and common cause events in particular, were not unique. The fundamental difference between the dependent and independent events was that the former has a coupling mechanism to transmit the effect of the trigger to two or more components, and the latter exhibited no such coupling mechanism(s). Examples of coupling mechanisms were functional dependence, spatial proximity, and human interactions. The distribution of the common cause triggers as a fraction of the overall common causes are listed below.
Based on these common cause fractional distribution reported in the EPRI study, CMDDs on an average accounted for approximately 25% of the EPRI beta BPM values. The first four common cause triggers listed were more basically grouped in the EPRI report as human-related causes and accounted for approximately 50% of the overall common cause failure contributions.
Common Cause (Trigger) Fractional Distributions
(1) CMDDs* 0.25
(2) Erroneous Procedures 0.10
(3) Other Plant/Staff Errors (including maintenance) 0.16
(4) Testing (not including instrumentation calibrations) 0.01
(5) Internal Causes 0.15
(6) Environmental Stress 0.08
(7) Unknown 0.19
(8) Multiple Causes 0.06
* - CMDDs consist of design, manufacturing, construction, and installation errors.
It was assumed that the unforeseen CMDDs from plant modifications and equipment replacements would continue at the approximate rate evaluated from the EPRI data base of dependent failures that occurred over the 400 to 600 RY of operation. Since the component/systems unavailabilities used in plant PRA analyses contained various components/systems with various beta (common cause) values, it was assumed that the average 25% contribution attributed by EPRI to CMDDs was generally applicable to all component/system beta BPM values.
Core-Melt Frequency Contribution from Unforeseen CMDDs: NUREG-11501081 provided a sensitivity study of the effects of common cause failures on severe core damage frequencies using four plant PRAs: Surry, Peach Bottom, Sequoyah, and Grand Gulf. The results in brief showed that dependent failures were basically plant-specific and subject to large variations from plant to plant, and that dependent failures were a major contribution to severe core damage frequency and, in some cases, risk. The NUREG-11501081 sensitivity study adjusted each of the PRA dominant accident sequences of the 4 plants to account for plant-specific, generic, and upper bound common cause beta values. The analyses also included base-case core-melt frequencies with beta set equal to zero to identify the overall contribution and sensitivity of severe core damage to the range of common cause beta values.
The pertinent NUREG-11501081 upper bound results and the generic mean value estimates were tabulated in Table 3.125-1. The mean values of the generic beta values were based on a log normal distribution with an error factor of 3. Based on the results in Table 3.125-1, the average core-melt frequency for the four plants, considering the mean value common cause beta BPM values, was 9.2 x 10-5 /RY. This average core-melt frequency was assumed representative of the generic core-melt frequency for all operating plants. Use of average values smoothed the outlier high and low plant-specific vulnerabilities to common cause failures and was more appropriate for a generic plant analysis (if indeed there was a generic plant).
As evident from the Table 3.125-1 tabulation, the contributions to plant-specific core-melt frequencies from all common cause contributors varied by approximately an order of magnitude, indicating the large plant-specific effect on core-melt frequency from common cause type failures. The contribution to the average core-melt frequency from common cause failures was (0.427)(9.2 x 10-5/RY) = 3.9 x 10-5/RY. Using 25% of the common cause contribution to account for only the unforeseen CMDDs yielded a core-melt frequency contribution of 9.8 x 10-6/RY from unforeseen CMDDs. Put another way, 42.7% of the generic plant core-melt frequency was attributed to estimated common cause failures (a significant contribution), where 10.7% of the core-melt frequency was attributed to estimated unforeseen CMDDs.
Frequency of Detecting Unforeseen CMDDs: It was expected that, in the majority of tests performed to simulate normal or off-normal plant operations, initiation and operation of safety systems, where systems are manually started, stopped, restarted, realigned, throttled, or otherwise operated in ways not easily anticipated by the designer, the system will usually work as expected.
Table 3.125-1Core-Melt Frequency Contributions
| Plant | Beta = 0 (A) | Beta BPM Contributions | (A+C) | (C) (A+C) | |
|---|---|---|---|---|---|
| Upper Bound Values (B) | Mean Values (C) | ||||
| Surry | 1.5 x 10-5 | 2.1 x 10-5 | 8.8 x 10-6 | 2.4 x 10-5 | 0.367 |
| Peach Bottom | 3.4 x 10-6 | 7.6 x 10-6 | 3.1 x 10-6 | 6.5 x 10-6 | 0.472 |
| Sequoyah | 7.1 x 10-5 | 5.7 x 10-4 | 2.4 x 10-4 | 3.1 x 10-4 | 0.774 |
| Grand Gulf | 2.3 x 10-5 | 6.0 x 10-6 | 2.5 x 10-6 | 2.6 x 10-5 | 0.096 |
| Average | - | - | - | 9.2 x 10-5 | 0.427 |
To estimate the likelihood of detecting an unforeseen CMDD, the experience of the Davis-Besse AFW system was considered. At the time of the June 9, 1985 event, this plant had accumulated about 6.8 calendar-years of operation. Loss of main feedwater (LMFW) events occurred roughly at a rate of 3/RY, so the June 9, 1985 LMFW event was preceded by roughly 15 AFW system actuations (assuming a 25% average outage time). Note that these actuations were only system initiations. Three loss of feedwater events per year corresponded to all feedwater losses, most of which were partially or easily recoverable. At the same time, the problems in the Davis-Besse AFW system and its associated controls and valving were there all along, but were not discovered (detected) until about 15 actuations had occurred. This limited plant-specific (Davis-Besse) information inferred that the probability of detecting an unforeseen CMDD, with the coupling mechanism(s) attributed to off-normal or unusual operation, was approximately 1/15 or 0.067/event.
Alternately, if the information contained in the EPRI report745 involving 255 AFW failure events was considered, only three of the events exhibited the necessary coupling mechanisms to detect common cause failures. Combining the Davis-Besse event with the 255 EPRI events indicated that the chance of detecting a common cause failure in PWR AFW systems per event was small (on the order of 0.01/event).
Additional evidence of the CMDD detection chance was suggested by other EPRI data. As discussed earlier, the fundamental difference between independent and dependent event failures was that the dependent, and common cause event failures in particular, must include a coupling mechanism(s) to transmit the effect of the trigger (cause) to two or more components. Therefore, the 68 events in the EPRI data base of 2,654 events that involved two or more actual failed or functionally unavailable states must have included some form of coupling mechanism(s). This would also suggest a detection (coupling) chance of approximately 0.03/event for a broader range of equipment and causes. Averaging the above operating experiences, it was estimated that the probability of detecting a significant number of CMDDs during each plant-specific test program was 0.035.
Because the above estimates were based on data of events involving failures, they should not be confused with a per demand rate of components/systems. If a demand rate of components/system were considered, it would need to be factored into the above estimate to obtain the chance of common cause failures per test demand. Therefore, use of the above ratios to estimate the chance of detecting unforeseen CMDDs during a one-time series of tests may be biased toward a conservative estimate, since it is conditional on the given occurrence of some random or induced human/component/system failure during the test. Normally, one would not expect either independent or dependent failures to occur during the course of a transient or test. However, this estimate was sufficient for this analysis.
Reduction in Core-Melt Frequency: Based on the previous calculations, the potential core-melt frequency contribution from unforeseen CMDDs, prior to the test program, was estimated to be 9.8 x 10-6/RY. After the tests, the core-melt frequency was weighted by the probability of the CMDDs not detected: (1 - 0.035) = 0.965. Therefore, the reduction in core-melt frequency from detecting and correcting the unforeseen CMDDs was:
![]() CMF = (1 - 0.965)(9.8 x 10)/RY = 3.4 x 10/RY
CMF = (1 - 0.965)(9.8 x 10)/RY = 3.4 x 10/RY
Consequence Estimate
The conditional release doses used in this analysis were based on the fission product inventory of a 1120 MWe PWR, meteorology typical of a midwest site, a surrounding uniform population density of 340 persons per square mile within a 50-mile radius of the plant, an exclusion radius of one-half mile from the plant, no evacuation, and no ingestion pathways. Therefore, the estimated change in risk was representative of the hypothetical generic PWR plant and was not representative of any specific plant. For BWR plants, the results were not expected to be greatly different.
Based on NUREG/CR-2300,187 the probability of a large release (5.1 x 106 man-rem/CM) was 0.2 and the probability of a basemat melt-through type release (1.5 x 105 man-rem/CM) was 0.8. Over a plant life of 30 years, the resulting estimated risk reduction associated with this issue was (3.4 x 10-7/RY)(1.2 x 106 man-rem)(30 years) or 12 man-rem/reactor.
Cost Estimate
A thorough integrated systems/plant test program that modeled various systems/plant responses to off-normal and DBE accident events would be a major undertaking and highly plant-specific for all operating plants. The dominant costs were likely to be replacement power costs that could result from a test-extended outage. Design, engineering, plant hazard analysis, labor, and modification costs to ready the plant for such a test program would be significant. These costs were also highly plant-specific, but were not estimated. However, prior to implementation of the test program, a long lead time could be expected to be required for the licensee to develop, and for the NRC to review and approve, the test programs. A less rigorous test program was possible and less costly if the test program could be accommodated largely within the normal refueling outage (7 weeks) with an estimated additional 3 week (0.7 month) outage extension.
The long lead time for a thorough test program, and the assumed necessity to phase-in all the plant (approximately 100 reactors) test programs over a specified time, to reduce the potential impact of lost electrical generation production from multiplant outages, were further considerations that would need to be considered in a more complete value/impact assessment of this issue because simultaneous (multiplant) outages tend to increase the costs of replacement power.
Replacement Power Costs: Based on the discussion provided before, a test program similar to the Rancho Seco restart test program may be needed to approach the Finding 15 recommendation that initiated this issue. It was assumed that the test programs would be a one-time series of tests for each plant and that the test programs could extend a plant refueling outage by 3 weeks (0.7 month) to 7 months, depending on the plant-specific test program and other tests scheduled to be performed during each plant's refueling outage. Using an average replacement power cost of $500,000 per day, the replacement power costs were estimated to be $11M to $110M per plant.
Plant Costs During Test-Extended Outage: It was difficult to provide detailed cost estimates of plant costs incurred during the test-extended outage period. These costs would involve engineering, management, labor, maintenance, and possibly some repair or modification costs. To estimate the plant costs during the test-extended outage period alone, it was assumed that the plant costs could be approximated by plant costs typically experienced from a forced outage. Based on NUREG/CR-3673,1082 this cost was estimated at $1,000/hour. For a test-extended outage of 3 weeks to 7 months, the plant costs were estimated to be between $0.5M and $5M per plant.
Combined Costs: The combined cost of replacement power and plant costs during a test-extended outage could range from $11.5M to $115M per plant. These combined costs do not include the significant but unquantified pre-implementation costs of the test program. However, this incomplete cost estimate provided insight into the large expense that may be involved in conducting a thorough integrated systems/plant test program for each operating plant. In addition, the NRC costs to review, approve, and follow the test programs in all operating plants would likely involve a large expenditure of NRC resources. For the optimistic outage extension of 3 weeks, the combined industry and NRC pre-implementation costs may approach the $11.5M cost of a short extended outage.
Value/Impact Assessment
(a) Long Extended Outage: Based on the risk reduction estimated to result from probable test identification and correction of unforeseen CMDDs (which was the focused goal of Finding 15) and the estimated range of the per-plant extended outage costs from the test programs, the range of the value/impact scores for this issue resolution was:

(b) Short Extended Outage: Assuming that the integrated systems/plant DBE testing phase could be conducted in 10% of the time estimated by Rancho Seco for their integrated systems/plant testing, then the value/impact score was given by:
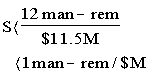
However, the latter priority score could be overly optimistic because pre-implementation costs will take on more significance and could approach the $11.5M estimated for only the replacement power costs and plant costs.
Other Considerations
Due to the involved complexities and the long lead time before these test programs could be implemented, the test programs would not likely commence until the mid-1990s. Even if the programs for the 100 operating plants were phased over the following five-year time period (20 plants/year), the test programs would not be completed until the year 2000. During these time periods, a significant amount of operational experience would significantly expand the data base and corrections for many of the unforeseen CMDDs through other ongoing industry and NRC programs, e.g., improved LER requirements, Bulletins, Information Notices, NRC Generic Issues Program, the Safety Systems Functional Inspections (SSFI) Program, and the Individual Plant Examinations (IPE) Program, would be made. Therefore, the goal of Finding 15 to detect and correct unforeseen CMDDs may, to a significant degree, be achieved before the test programs can be initiated and completed. CMDDs that may result from plant modifications or equipment replacements that follow the test programs would also not be eliminated by the one-time test programs.
CONCLUSION
The stated goal of the proposed integrated systems/plant test programs of Finding 15 is to detect and correct unforeseen CMDDs. The Finding 15 recommendation to use integral plant/system testing, as near as practical to DBA conditions, to detect CMDDs seemed too limited in its goal, considering the potentially large expenditure of time and resources that could be needed to develop the program. As evident by this analysis, the existing state-of-the-art on CCFs was lacking sufficient information (data) and knowledge concerning coupling mechanisms that trigger CCFs. Without sufficient information (data) on the individual plants and a better understanding of the CCF coupling mechanisms, the successful result of the Finding 15 recommendation appeared unlikely. The estimated success probability of the tests to detect all unforeseen CMDDs resulted in a potential reduction in core-melt frequency of 3.4 x 10-7/RY. This reduction in core-melt frequency bordered between a drop and low on the priority ranking matrix (see Appendix C).
The risk reduction, not considering a time-averaged dilution before the tests would yield any benefits (risk and core-melt frequency reductions) as discussed above, was estimated at 12 man-rem/plant. This reduction bordered between a drop and low on the priority matrix (see Appendix C).
The above risk reduction, when divided by the large costs that could be involved in such a program, yielded an estimated priority score in the range of less than 1 to 0.1 man-rem/$M. This value/impact range was approximately three to four orders of magnitude less cost-effective than the 1,000 man-rem/$M that was generally considered to be a cost-effective resolution. However, due to the low risk reduction, the priority ranking was not affected by the estimated range of the priority scores for the issue.
The above results were based on mean generic beta values applied to four plant PRAs and the resultant average core-melt frequency of the four plants. This approach smoothed out high and low plant-specific vulnerabilities to common cause type failures and was more representative of a hypothetical generic plant. Therefore, the results of this hypothetical generic plant analysis should not be construed to be representative of any specific plant, since plant-specific vulnerabilities to common cause type failures vary significantly from plant to plant.
It must also be recognized that the analysis of this issue was directed toward using thorough integrated systems/plant testing of DBE conditions (as near as practical) to detect and correct unforeseen CMDDs. In this regard, Finding 15 explicitly stated that thorough integrated systems/plant tests under these conditions were essential for the detection and correction of unforeseen CMDDs. This analysis did not support Finding 15 as an essential and practical solution for detecting and correcting unforeseen CMDDs. This was true even considering that, in the analysis, a wide range of time (3 weeks to 7 months) and cost ($11.5M to $115M) that would be incurred by a utility in doing integral testing were evaluated. These estimates did not include considerable engineering, procedure development, and training costs that would also be incurred in preparing to run such tests. In addition, it was proposed that such tests could be valuable in uncovering other CCFs from the triggers shown before. While it was theoretically possible to use integral testing for this purpose, the test program required would have to be more extensive and be done at periodic intervals to be effective in uncovering other common cause triggers. Such a test program went far beyond what was evaluated for addressing CMDD (a one-time test program) and, based upon the work done in this analysis, would have had even less justification for pursuing.
The potential time that may be needed to develop, implement, and reach the Finding 15 resolution was considered. Based on this timing consideration and the apparent and expected continued success of other NRC actions, such as improved LER requirements, Bulletins, Information Notices, the Generic Issues Program, the SSFI Program, and the IPE Program, the detection and correction of unforeseen CMDDs, to a significant degree, may have been achievable before the Finding 15 resolution could be achieved. Thus, the potential benefit in detecting and correcting unforeseen CMDDs through the Finding 15 resolution could be further reduced by the above timing considerations and success of other ongoing actions and programs. In addition, it should be recognized that these other ongoing actions and programs represented a way of uncovering and correcting CMDDs short of an integral testing program.
Based on the results and other considerations discussed above, the proposed solution to develop and implement thorough integrated systems/plant test programs under abnormal or accident conditions, as an essential and practical solution to detect and correct unforeseen CMDDs in all operating reactors, was placed in the DROP category (see Appendix C).
However, an alternate approach to the Finding 15 recommendation would be to assess the benefit of improvements in existing in-service, refueling, and surveillance testing programs in operating reactors, and improved startup testing for future plants. Such an assessment would focus on improvements in testing components and systems under conditions more representative of operational and DBE expectations, with emphasis directed toward detection of all types of CCFs, and not singularly CMDDs. This alternate approach, however, would be more effective as a long-term program. In this regard, the alternate approach would make use of results from the IPE program and other ongoing programs identified above. In brief, the IPE program PRA methods were expected to include specific guidelines1119 and procedures for treating CCFs in the plant-specific PRAs. These IPE-PRA results could be a valuable tool for identifying potential CCFs, in structuring surveillance testing strategies, and in the design of hardware and modifications, or improving operating procedures. This alternate approach was assessed separately in Issue 145, "Actions to Reduce Common Cause Failures."
ITEM 125.I.6: VALVE TORQUE, LIMIT, AND BYPASS SWITCH SETTINGS
DESCRIPTION
Historical Background
One of the primary sources of failure of the Davis-Besse AFW isolation valves to reopen (see Issue 122.1) was ultimately traced to the torque, limit, and bypass switches which control the motor operators of the valves.940 During the event, these valves were closed due to an operator error, shutting off all AFW flow. Once closed, the resulting high differential pressure across the closed valves necessitated a relatively large force to start valve motion. The valve motor-operator torque bypass switches were not adjusted to accommodate such a force and manual operation was needed to reopen the valves.
Issue 122.1.a, "Failure of Isolation Valves in Closed Position," specifically dealt with the case of AFW isolation valves. However, at least some of the other MOVs in the plant are designed by the same people that designed the AFW system, and virtually all the valves in the plant are maintained by the same crews. Therefore, the problems with torque, limit, and bypass switch settings were not limited to AFW systems but could affect any MOV in the plant. Moreover, such problems had a high potential for causing common mode failures since redundant trains were probably maintained by the same maintenance personnel.
Safety Significance
The safety concern of this issue was exactly that of IE Bulletin No. 85-03,1036 "Motor-Operated Valve Common Mode Failures During Plant Transients Due to Improper Switch Settings." This Bulletin required all licensees to develop and implement a program to ensure that valve operator switches were selected, set, and maintained properly for all valves in the high pressure injection, core spray and emergency feedwater systems (including BWR RCIC), that are required to be tested for operational readiness in accordance with 10 CFR 50.55a(g).
Possible Solution
IE Bulletin 85-031036 was expected to resolve the safety concern of this issue for switch settings on valve operators in the specified safety systems. The extension of this issue to other valves and/or extension of the issue to more general testing adequacy also needed to be considered. However, the general question of test adequacy for all safety-related valves was addressed in Issue II.E.6.1, "Test Adequacy Study," and there was no need to extend or generalize Issue 125.I.6.
CONCLUSION
The safety concern of this issue was addressed by IE Bulletin 85-031036 and in the resolution of Issue II.E.6.1. Thus, Item 125.I.6 was DROPPED from further pursuit as a new and separate issue.
ITEM 125.I.7: OPERATOR TRAINING ADEQUACY
This item was broken down into two parts that were evaluated separately as shown below.
ITEM 125.I.7.A: RECOVER FAILED EQUIPMENT
DESCRIPTION
Historical Background
This issue was based on Finding 8 of the Incident Investigation Team's (IIT) report886 which stated: "The operators' understanding of procedures, plant system designs, and specific equipment operation, and operator training all played a crucial role in their success in mitigating the consequences of the event. However, if the equipment operators had been more familiar with the operation of the auxiliary feedwater pump turbine trip-throttle valve, auxiliary feedwater could have been restored several minutes sooner."
During the Davis-Besse event, both AFW turbines tripped on overspeed. These trips were not remotely resettable from the control room but instead had to be reset manually at the turbines. Two equipment operators were dispatched to the AFW turbines but were unable to get the turbines running because they had never performed this operation before. (At the time of the initial evaluation of this issue in December 1987, hands-on practice of this task was not a part of operator training.) The turbines were not started until after the arrival of a more experienced operator.
Safety Significance
The safety significance of this issue was in the probability of non-recoverability of safety systems. In many cases, a given train of a given system may trip or otherwise fail to start on first demand, but may still successfully be placed in operation by prompt, knowledgeable human intervention.
Possible Solution
TMI Action Plan Items I.A.2.2 and I.A.2.6 have addressed the issue of training and resulted in a policy statement966 that endorsed the INPO-managed training accreditation program which included an element to ensure that feedback from operating events is included in all utility training programs. NRC monitors and evaluates industry implementation of the INPO accreditation program to ensure that: (1) plant personnel are able to meet job performance requirements; (2) training properly accounts for pertinent safety issues; and (3) mechanisms exist for upgrading and assuring the quality of training programs. Criteria to evaluate the industry training programs were developed in NUREG-1220993 in the resolution of Human Factors Issue HF2.1.
CONCLUSION
This issue was resolved by the issuance of the Commission Policy Statement966 on Training and Qualifications and by Issue HF2.1. Therefore, the issue was DROPPED from further pursuit as a new and separate issue.
ITEM 125.I.7.B: REALISTIC HANDS-ON TRAINING
DESCRIPTION
Historical Background
The issue called for an assessment of the adequacy of hands-on training with respect to conditions that may be encountered in realistic situations, such as the loss of feedwater event that occurred at the Davis-Besse plant on June 9, 1985.940 The assessment could involve the operator's understanding of procedures, plant systems designs, specific equipment operations, and hands-on training in handling plant transient and upset conditions.
The issue stemmed from Findings 8 and 16 of the NRC investigation886 of the Davis-Besse event in which the NRC staff noted that the post-TMI improvements that focused on EOPs and training played a crucial role in mitigating the Davis-Besse event. However, if the equipment operators had been more familiar with the operations of the AFW pump turbine trip throttle valve, AFW could have been restored several minutes sooner. Also, for events such as the Davis-Besse event involving conditions outside the plant design basis (multiple equipment failures), operator training and operator understanding of systems and equipment are crucial to the likelihood that plant operators can successfully handle similar events.
Safety Significance
Assessments of the hands-on experience, referred to as performance-based training or Systems Approach to Training (SAT), are considered essential to providing assurance that nuclear power plants are operated in a safe state under all operating conditions. This issue affected all operating nuclear power plants.
Possible Solution
TMI Action Plan48 Items I.A.2.2 and I.A.2.6 included development of procedures to provide assurance that: (1) plant personnel are able to meet job performance requirements; (2) training properly account for pertinent safety issues; and (3) mechanisms exist for upgrading and assuring the quality of training programs.
To help meet these objectives, NUREG-1220993 was developed for use by NRC personnel to review the INPO-managed performance-based training programs in nuclear power plants. NRC was expected to continue to closely monitor the process (INPO Accreditation) and its results to independently evaluate implementation of these programs. The NRC review procedures developed in NUREG-1220993 considered the following five elements as essential to these training programs: (1) systematic analysis of the jobs to be performed; (2) learning objectives that are derived from the analysis and that describe desired performance after training; (3) training design and implementation based on the learning objectives; (4) evaluation of trainee mastery of the objectives during training; and (5) evaluation and revisions of the training based on the performance of trained personnel in job settings (hands-on experience).
In accordance with NUREG-0985,651 the training issues included the closeout of the following TMI Action Plan48 items: I.A.2.2, "Training and Qualifications of Operations Personnel"; I.A.2.7, "Training Accreditation"; I.A.2.5, "Plant Drills"; and I.A.2.3, "Administration of Training Programs." The specific issue of realistic hands-on training on equipment such as AFW pumps is a performance-based element of on-the-job training (OJT). As such, mastery is determined by completion of a job qualification card to the satisfaction of a qualified OJT instructor using approved evaluation criteria. The INPO Accreditation Program was intended to provide assurance that such training is included in industry programs. NRC evaluates industry implementation of the Accreditation Program in accordance with the Policy Statement on Training and Qualification.966
CONCLUSION
Based on the above discussion, this issue was covered by the Policy Statement966 on training and Qualifications and by the Human Factors Issue HF3.1. Therefore, the issue was DROPPED from further pursuit as a new and separate issue.
ITEM 125.I.8: PROCEDURES AND STAFFING FOR REPORTING TO NRC EMERGENCY RESPONSE
DESCRIPTION
Historical Background
This issue was based upon Finding 12 of the IIT report886 which stated: "The event was not reported to the NRC Operations Center in a manner reflecting the safety significance of the event. The more serious the event, the more operator involvement required to maintain plant safety. For example, if the June 9 event had been protracted, knowledgeable personnel would not have been available to maintain an open telephone line with the NRC."
Safety Significance
It was evident from the IIT report886 of the event that there were two problems: one associated with staffing and one associated with procedures. The staffing problem was that all knowledgeable personnel were kept busy in dealing with the event. No one could be spared to keep the NRC Operations Center informed. Moreover, even if more plant staff had been available, it was likely that these additional persons would have been pressed into service for plant operations. Of course, bringing the plant to a safe condition does and should have priority. But this also called into question the usefulness of the dedicated phone lines to the NRC Operations Center.
The procedural problem was evident in the fact that there was confusion because the emergency plan was silent on how to determine the emergency action level if the emergency classification changed during the event. Obviously, the emergency procedures contained some ambiguity.
For both problems, the result was a delay in notification of the NRC Operations Center. Although it could be argued that notification of the NRC could have little or no effect on plant events in the short term, the NRC can provide technical support and assistance over a period of several hours. Moreover, the NRC can assist in coordinating evacuations, etc., if such should ever prove necessary. Finally, the NRC has other responsibilities not directly related to plant safety but nevertheless of importance, such as providing accurate and timely information to the public, other government agencies, and the governments of other nations.
CONCLUSION
The staffing problem was a duplication1003 of the concern of TMI Action Plan48 Item III.A.3.4, "Nuclear Data Link," which was resolved. In addition, the procedural problem had already been addressed1003 in regulatory requirements (10 CFR 50.72) and IE Information Notice No. 85-80. Furthermore, the IE Manual addressed the NRC regional responsibility for assuring that reporting requirements are met.1003 Therefore, the issue was DROPPED from further pursuit as a new and separate issue.
ITEM 125.II.1: NEED FOR ADDITIONAL ACTIONS ON AFW SYSTEMS
During the event, the main feedwater system was lost and the reactor scrammed. The AFW system should have activated and supplied feedwater to the steam generators to enable them to remove decay heat. However, during the course of the event, several failures occurred (see Issue 122) that precluded using the steam generators to remove decay heat from the primary system. The event highlighted the importance of the AFW system and also demonstrated that the AFW system might not have a reliability commensurate with its importance.940
If the main feedwater system shuts down for any reason, the AFW system will supply sufficient feedwater to the steam generators to remove reactor decay heat. If the AFW system were to fail also, there would be no feedwater supply at all. The steam generators would boil off their remaining liquid water inventory and then dry out. Depending on specific plant design, core uncovery will take place roughly 30 to 90 minutes after the transient begins. After steam generator dryout, there would be no decay heat removal and the continuing thermal energy production in the core would result in primary system heatup.
In most cases, the only means of decay heat removal involve use of the AFW system, recovery of the main feedwater system, or the use of feed-and-bleed techniques. Of the three means, the use of the AFW system is subject to the highest availability. The failure of the main feedwater system has roughly a 20% probability of not being recoverable in time. Moreover, use of feed-and-bleed techniques will release primary coolant to the containment necessitating extensive (and expensive) cleanup. The use of feed-and-bleed techniques, which remove decay heat by venting hot primary coolant to the containment and replacing the lost inventory in the primary system by means of the high pressure ECCS, could still prevent core uncovery. If feed-and-bleed fails, the primary system will increase in temperature and pressure to the point where the primary system safety valves open. The pressure increase will then terminate, but the primary coolant will boil off until the core is uncovered and melts.
AFW systems are safety-grade systems. In addition, the availability of feed-and-bleed techniques provides a diverse backup. Nevertheless, AFW reliability is very important for two reasons. First, loss of main feedwater is a relatively common event, occurring roughly three orders of magnitude more often than (for example) small break LOCAs. Thus, the AFW system is challenged far more often than the high pressure ECCS and therefore has a commensurately greater need for high reliability. Second, although feed-and-bleed techniques provide a backup to AFW for removing reactor decay heat, feed-and-bleed is a means of core cooling for which the plant was not designed and may have a relatively high failure probability (see Item 125.II.9). Because of these two reasons (frequent challenges and poor backup capability), it is very important that the AFW system have very high reliability.
Because loss of feedwater events are relatively frequent, the AFW system is subject to frequent challenges. Therefore, the AFW system must be characterized by very high availability. This issue consists of four parts, each of which sought to ensure adequate AFW reliability:
(a) Two-Train AFW Unavailability
This issue was concerned that AFW systems consisting of only two-trains may not have adequate reliability.
(b) Review Existing AFW Systems for Single Failures
This issue sought confirmatory deterministic reviews of AFW systems at operating plants to ensure that they met the single failure criterion.
(c) NUREG-0737 Reliability Improvements
This issue proposed that PRA analyses (i.e. fault trees) be performed on AFW systems at operating plants to ensure adequate reliability.
(d) AFW Steam and Feedwater Rupture Control System/ICS Interactions in B&W Plants
This issue was concerned explicitly with a possible design problem at B&W plants.
These four parts of the issue were evaluated separately below.
ITEM 125.II.1.A: TWO-TRAIN AFW UNAVAILABILITY
DESCRIPTION
There were seven older PWRs that have two-train AFW systems. (Originally, there were more but some plants had added a third train or made other equivalent upgrades). These AFW systems generally consisted of one motor-driven train and one turbine-driven train and thus possessed some diversity as well as redundancy. However, the turbine-driven trains had not proven to be as reliable as the motor-driven trains (except, of course, for the case where all AC power is lost). The more modern practice had been to use a three-train system where two trains are motor-driven and one is driven by a steam turbine. Such a system would, in principle, be more reliable than the two-train systems described above, both because of the greater redundancy of the three vs. two trains and because of the lower reliance on the steam turbine.
CONCLUSION
This issue was the same as Issue 124, "AFW System Reliability," which considered whether AFW system unavailability needed to be improved for plants with two-train designs.947 Therefore, this issue was DROPPED from further pursuit as a new and separate issue.
ITEM 125.II.1.B: REVIEW EXISTING AFW SYSTEMS FOR SINGLE FAILURE
DESCRIPTION
Historical Background
The AFW system is considered an engineered safety feature and thus is required to meet the single failure criterion which can be considered a very primitive reliability requirement. An unsuspected single failure susceptibility could increase the AFW system failure probability by two orders of magnitude or more.
Safety Significance
The issue addressed the concern that there may be some unsuspected single failures which were not detected during the licensing process. Therefore, this issue proposed to re-review the AFW systems of all operating PWRs to make doubly sure that no single failures existed which, by themselves, could cause all AFW trains to fail.
Possible Solution
The systems to be examined had already been subjected to licensing review. Therefore, any single failures were not going to be obvious, but instead were likely to be quite subtle. Very thorough reviews would be required. It must also be remembered that AFW trains are intentionally designed to be independent. Any single failure found would most likely be a subtle design anomaly which the designer (as well as all subsequent reviewers) failed to notice.
Several AFW systems were examined by OIE in the course of the Safety System Functional Inspection (SSFI) program. Conversations with the SSFI team indicated that some single failure problems as well as other potential common mode failures had been found by this program. However, these problems were not discovered by examining system design, but instead arose in the course of very thorough investigations involving extended site visits, equipment inspection, and interviews as well as design reviews. Therefore, the proposed solution was not a simple design review, but instead was a more thorough investigation along the lines of the SSFI program.
Frequency Estimate
The sequence of interest was straightforward; it was initiated by a non-recoverable loss of main feedwater. If the AFW system fails, the SUFP is not re-enabled in time, and feed-and-bleed techniques fail, core-melt will ensue. An initiating event frequency (non-recoverable loss of main feedwater) of 0.64 event/RY was used, based upon the Oconee-3 PRA done by Duke Power Co.947 This figure was based on fault tree analysis and was reasonably representative of most main feedwater system designs.
For a three-train AFW system, a "typical" unavailability is 1.8 x 10-5/demand.894 The presence of a single failure susceptibility would greatly increase this figure to perhaps the square root of the original figures because half the redundancy would be removed. The change in AFW unavailability would then be about 4.2 x 10-3 failure/demand. A typical value of 0.20 for the failure probability of feed-and-bleed cooling was assumed, based upon the calculations presented under Issue 125.II.9, "Enhanced Feed-and-Bleed Capability." Multiplying these figures, the change in core-melt frequency was (0.64/year)(4.2 x 10-3)(0.20) = 5.4 x 10-4/year
Consequence Estimate
The core-melt sequence under consideration involved a core-melt with no large breaks initially in the reactor coolant pressure boundary. The reactor was likely to be at high pressure (until the core melts through the lower vessel head) with a steady discharge of steam and gases through the PORV(s). These are conditions likely to produce significant H2 generation and combustion.
The Zion and Indian Point PRA studies used a 3% probability of containment failure due to H2 (the "gamma" failure). This example was followed and 3% was used, with the consideration that specific containment designs can differ significantly from this figure. In addition, the containment can fail to isolate (the "beta" failure); here, the Oconee-3 PRA figure of 0.0053 was used. If the containment does not fail by isolation failure or H2 burn, it was assumed to fail by basemat melt-through (the "epsilon" failure).
Assuming a central midwest plain meteorology, a uniform population density of 340 persons/square-mile, a 50-mile radius, and no ingestion pathways, the consequences were:
| Failure Mode | Percent Probability | Release Category | Consequences (man-rem) |
|---|---|---|---|
| gamma | 3.0% | PWR-2 | 4.8 x 106 |
| beta | 0.5% | PWR-5 | 1.0 x 106 |
| epsilon | 96.5% | PWR-7 | 2.3 x l03 |
The "weighted-average" core-melt produced consequences of 1.5 x 105 man-rem.
At the time of the initial evaluation of this issue in October 1986, there were 80 PWRs operating or under construction. By March 1988 (the earliest that any hardware changes were likely to be made), these 80 plants were expected to have a combined remaining license life of 2,508.4 calendar-years. At a 75% capacity factor, this was about 23.5 years of operation per plant. Thus, the estimated risk reduction associated with the possible solution to this issue was (5.4 x 10-4) (23.5)(1.5 x 105) man-rem/reactor or 1,904 man-rem/reactor.
Cost Estimate
The SSFI program required about 1,000 staff-hours/plant and system at a cost of about $50,000 in salary and overhead. In addition, hardware changes were likely to cost on the order of $100,000/plant (i.e., more than $10,000 but less than $1,000,000), plus another $50,000 in paperwork. Thus, a cost on the order of $200,000/plant was assumed.
Value/Impact Assessment
Based on an estimated public risk reduction of 1,904 man-rem/reactor and a cost of $0.2M/reactor for a possible solution, the value/impact score was given by:

Other Considerations
(1) The AFW system and its support systems do not contain contaminated fluids and are located outside of containment. Thus, there was no ORE associated with the fix for this issue.
(2) Averted accident costs and averted cleanup exposure are considerations, but would only drive the priority score still higher. Thus, they would change no conclusions and were not considered.
(3) The high values of the parameters were predicated on finding at least one plant that needed upgrading. The SSFI personnel emphasized that this was not likely to happen without an approach similar to that of the SSFI, but such an approach was likely to bear fruit. Thus, it was feasible to incorporate this issue into the SSFI program.
CONCLUSION
Based upon the above calculations, this issue was given a high priority ranking (see Appendix C) but was later integrated into the Phase II activities in the resolution of Issue 124.973 Thus, this issue was covered in Issue 124.
ITEM 125.II.1.C: NUREG-0737 RELIABILITY IMPROVEMENTS
DESCRIPTION
Historical Background
After the TMI-2 accident, all PWR licensees were asked to perform an unavailability analysis of their AFW systems. At the time of the initial evaluation of this issue in October 1986, this information was somewhat out of date partly because the AFW systems were subject to some (NUREG-0737)98 modifications after the analyses were made,946 and partly because the analyses were rather primitive by updated standards.
Safety Significance
This issue sought to upgrade the AFW unavailability analyses to reflect the NUREG-073798 modifications and improvements and to ensure that the AFW system reliability was commensurate with the system's safety importance.
Proposed Solution
The proposed solution to the issue was to perform a PRA of all AFW systems and require modification of any systems that had an unacceptably high failure probability.
PRIORITY DETERMINATION
Issue 124, "AFW System Reliability," was expected to consider whether 7 PWRs with two-train AFW systems had AFW system unavailabilities that needed to be improved. Therefore, this issue covered only the three-train AFW systems.
To evaluate this issue, several questions needed to be answered. First, how reliable must the AFW system be to have a reliability commensurate with its safety importance? In Issue 124, an unavailability of 10-4 failure/ demand was selected as the upper limit of acceptability947 and this value was used. The second question was, how many plants are likely to be found that cannot meet the 10-4 failure/demand cutoff? Analyses of 10 three-train AFW designs were summarized in an RRAB/NRR memorandum894 as follows:
| Design | Failure/Demand | log(failure/demand) |
|---|---|---|
| Summer | 11.2 x 10-5 | -4.92 |
| McGuire | 2.0 x 10-5 | -4.70 |
| Comanche Peak | 2.0 x 10-5 | -4.70 |
| Diablo Canyon | 3.7 x 10-5 | -4.43 |
| San Onofre 2&3 | 2.2 x 10-5 | -4.66 |
| SNUPPS | 2.0 x 10-5 | -4.70 |
| Waterford | 1.4 x 10-5 | -4.85 |
| Midland | 1.0 x 10-5 | -5.00 |
| Seabrook | 2.0 x 10-5 | -4.70 |
| Catawba | 0.7 x 10-5 | -5.15 |
|
These 10 analyses could be considered a statistical sample. The cutoff of 10-4 failure/demand was 9.76 standard deviations above the mean on a linear scale and 3.55 standard deviations above the mean on a logarithmic scale. The shape of the distribution was unknown but both a normal and a log normal distribution were examined and the worst case was used. Based upon these distributions and, in the absence of any other information, if another three-train AFW design were evaluated, the probability of this new design being above the cutoff was:
|
What this meant was that 10 sample designs were all well below the cutoff. Had the sample average been close to just below 10-4, one would be confident of finding a plant or two over the limit. However, the mean was far below the limit (where "far" was defined in terms of the width of the distribution) and the per-plant probability of being over the limit was small.
Seven of the 80 plants considered had two-train AFW systems and were covered by Issue 124. Thus, 73 plants remained to be considered. The probability of detecting one or more of these plants with an AFW unavailability greater than 10-4/demand was:
1 - (1 - 2 x 10-4)73 (73)(2 x 10-4)![]() 0.014
0.014
Therefore, based upon the available knowledge regarding three-train AFW designs and with the absence of other information, a PRA of all three-train AFW systems had only a few percent chance of finding a system that needed upgrading. (This did not mean that these AFW systems were problem free. It meant that the problems probably would not be found by means of PRA, unless considerably more information was available.)
Frequency Estimate
The sequence of interest was straightforward: it is initiated by a non-recoverable loss of main feedwater. If the AFW system fails and feed-and-bleed techniques fail, core-melt will ensue. An initiating event frequency (non-recoverable loss of main feedwater) of 0.64 event/RY was used, based upon the Oconee PRA done by Duke Power Co.947 This figure was based upon fault tree analysis and was reasonably representative of most main feedwater system designs.
Next, the change in AFW failure probability was estimated. It was assumed that the AFW system "as is" had an unavailability equal to that of a "typical" two-train AFW system, which would be about 6.7 x 10-4/demand, the average of the 7 plants.948 The AFW system failure probability after upgrading would be at most 10-4. Therefore, the change in probability would be about 5.7 x 10-4.
A typical value of 0.20 for the failure probability of feed-and-bleed cooling was assumed, based upon the calculations presented in Issue 125.II.9, "Enhanced Feed-and-Bleed Capability." Multiplying these figures, the change in core-melt frequency was (0.64/year)(5.7 x 10-4)(0.20) = 7.3 x 10-5/year. The number of hypothetical plants needing modification (expectation value) was 0.014. Thus, the change in core-melt frequency for all reactors was 10-6/year.
Consequence Estimate
The core-melt sequence under consideration involved a core-melt with no large breaks initially in the reactor coolant pressure boundary. The reactor was likely to be at high pressure (until the core melts through the lower vessel head) with a steady discharge of steam and gases through the PORV(s). These are conditions likely to produce significant H2 generation and combustion. The Zion and Indian Point PRA studies used a 3% probability of containment failure due to H2 burn (the "gamma" failure). This example was followed and 3% was used, considering that specific containment designs could differ significantly from this figure. In addition, the containment could fail to isolate (the "beta" failure). Here, the Oconee PRA figure of 0.0053 was used. If the containment does not fail by isolation failure or H2 burn, it was assumed to fail by basemat melt-through (the "epsilon" failure).
Assuming a central midwest plain meteorology, a uniform population density of 340 persons/square-mile, a 50-mile radius, and no ingestion pathways, the consequences were:
| Failure Mode | Percent Probability | Release Category | Consequences (man-rem) |
|---|---|---|---|
| gamma | 0.3% | PWR-2 | 4.8 x 106 |
| beta | 0.5% | PWR-5 | 1.0 x 106 |
| epsilon | 96.5% | PWR-7 | 2.3 x 103 |
The "weighted-average" core-melt produced consequences of 1.5 x 105 man-rem.
Because this issue dealt with only an expectation value for the number of plants, but did not necessarily expect to affect any specific plant, the per-plant parameters (core-melt/RY and man-rem/reactor) were not meaningful. Instead, the "aggregate" parameters (core-melt/year and total man-rem) were appropriate.
By March 1988 (the earliest that any changes were likely to be made), the 73 subject plants would have had a combined remaining life of 2,317.8 calendar-years. At a 75% capacity factor, this amounted to an average of 23.8 years of operation remaining per plant. Therefore, the change in risk for the hypothetical plant was 11 man-rem/year and the total risk reduction for all reactors was 3.7 man-rem.
Cost Estimate
The cost of a solution would include administrative charges, preparation of PRAs, and possibly hardware changes, should they be required. It was not clear whether the PRAs would be done by the licensees or the NRC. In any case, the cost of the PRA of one AFW system was likely to be on the order of $50,000 or more (half a staff-year). For 73 plants, this was $3.65M. The administrative and hardware costs were not calculated but, instead, $3.65M was used as a minimum figure.
Value/Impact Assessment
Based on an estimated public risk reduction of 3.7 man-rem and a minimum cost of $3.65M for a possible solution, the value/impact score was given by:
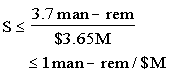
Other Considerations
(1) The statistical logic presented above did not rule out specific systems needing attention. The proper conclusion was that, unless more information was forthcoming (for example, specific design or performance problems), a non-specific general search such as this was difficult to justify, because there was no specific reason to believe a problem would be found this way, based on past experience. Also, the continuous distribution assumption implied that design anomalies, such as the single failures of Item 125.II.1.B, had been fixed. This item was not viewed in isolation.
(2) In addition to its attention to plants with two-train AFW systems in Issue 124, "AFW System Reliability," the staff was also considering whether to require confirmation that the remaining PWRs had AFW system reliabilities that were less than 10-4/demand. However, Issue 124 had not produced a decision at the time this issue was evaluated, nor did a decision appear to be forthcoming in the near future. Therefore, this issue could not be integrated into Issue 124.
(3) In most cases, the fix would not involve work within radiation fields and thus would not involve ORE.
(4) The ORE averted due to post-feed-and-bleed cleanup and post-core-melt cleanup was a minor consideration. ORE associated with cleanup was estimated to be 1,800 man-rem after a primary coolant spill and 20,000 man-rem after a core-melt accident.64 If the frequency of feed-and-bleed events was 5 x 10-6/year, the actuarial cleanup ORE averted was only 0.2 man-rem. Similarly, a total core-melt frequency of 10-6/year corresponded to an actuarial averted cleanup ORE of only 0.5 man-rem. If averted ORE were added to the man-rem/reactor and man-rem/$M figures above, no conclusions would change.
(5) The proposed fix would reduce core-melt frequency and the frequency of feed-and-bleed events and, therefore, would avert cleanup costs and replacement power costs. The cost of a feed-and-bleed usage was dominated by roughly six months of replacement power while the cleanup was in progress. If the average frequency of such events was 5 x 10-6/year and the average remaining life was 31.7 calendar-years at 75% utilization, then with the usual assumptions of a 5% annual discount rate and a replacement power cost of $300,000/day, the actuarial savings for feed-and-bleed cleanup would be $3,300. Similarly, the actuarial savings of averted core-melt cleanup (which was assumed to cost one billion dollars if it were to happen) would be about $12,000. The actuarial savings from replacement power after a core-melt up to the end of the plant life were also about $12,000. (This last figure represented the lost capital investment in the plant.) If these theoretical cost savings were subtracted from the expense of the fix, the man-rem/$M would not change significantly.
CONCLUSION
Based on the above calculations, the issue was placed in the DROP category (see Appendix C).
ITEM 125.II.1.D: AFW/STEAM AND FEEDWATER RUPTURE CONTROL SYSTEM/ICS INTERACTIONS IN B&W PLANTS
DESCRIPTION
This issue was centered on the subject of the reliability of the AFW system which is safety-grade. It was targeted specifically at B&W plants940 and required a reexamination of the AFW system reliability.948 The reasons given were two-fold. First, assessments made shortly after the TMI-2 accident indicated that the AFW system in B&W plants had (at that time) an unavailability approximately an order of magnitude higher than those in most other PWRs.948 (This did not account for the subsequent modifications to these AFW systems.) Second, this issue called for explicit attention to the interactions between the AFW system and the SFRCS and between the AFW system and the Integrated Control System (ICS). Such interactions are important because the initiating transient may well be caused by a problem with the ICS and any possible interactions between the ICS and AFW or SFRCS would be a potential source of a common mode failure, defeating the system needed to mitigate the transient.
PRIORITY DETERMINATION
On the general question of AFW unavailability, the B&W plants had already updated their reliability analyses to reflect the post-TMI modifications.946 These updates satisfied the original concern.949
The specific issue of the ICS-SFRCS-AFW interactions deserved more discussion. The function of an SFRCS is to control the AFW system. The name (Steam and Feedwater Rupture Control System) is somewhat misleading in that the SFRCS also initiates AFW for loss of main feedwater events. Those plants with an SFRCS should have no interactions between the ICS and the SFRCS or AFW systems.
At the time of the initial evaluation of this issue in October 1986, there were some B&W plants that had used the ICS to control the AFW system. Of these, two plants (Crystal River and ANO-1) had installed an "Emergency Feedwater Initiation and Control (EFIC) System" to replace the ICS as the control system for AFW. (The EFIC system was an improvement over SFRCS in that the EFIC system will not allow both steam generators to be isolated simultaneously. The SFRCS at Davis-Besse was also modified such that it would no longer allow both steam generators to be isolated simultaneously.) Of the two remaining plants, Rancho Seco was expected to install an EFIC system at its next refueling outage, and TMI-1 was expected to install a system similar to EFIC, but designed by the licensee, at its next refueling outage.
Under these circumstances, the concern was not with SFRCS-AFW interactions, but instead was reduced to ensuring that there was no interaction between the ICS and the AFW or its control system that could cause a common mode failure. For plants with two-train AFW systems, this was expected to be covered by the analyses of Issue 124.947, 949 The remaining plants were to be examined in the B&W Reassessment Program which placed considerable emphasis on the ICS.950
CONCLUSION
This issue was covered in Issue 124 and the B&W Reassessment Program and was DROPPED from further pursuit as a new and separate issue.
ITEM 125.II.2: ADEQUACY OF EXISTING MAINTENANCE REQUIREMENTS FOR SAFETY-RELATED SYSTEMS
DESCRIPTION
Historical Background
The objective of this issue was to assess the adequacy of existing maintenance requirements and their impact on the reliability of safety-related systems.940 The IIT concluded that the underlying cause of the Davis-Besse event was the licensee's lack of attention to detail in the care of plant equipment.886
Safety Significance
Inadequate and/or improper maintenance of equipment, components, and systems relied on for safe operations of the plants can lead to loss of safety functions. The loss of safety functions of the safety-related systems can increase the severity of transients and lead to severe core damage and possibly a core-melt. Given a core-melt and loss of containment integrity, public radiation exposure would result from the release of fission product materials. The issue was applicable to all operating nuclear power plants.
Possible Solutions
For the Davis-Besse plant, the staff conducted a maintenance survey consistent with the NRC Maintenance and Surveillance Program Plan (MSPP) as a result of the IIT conclusions.886 As a result of this survey, the staff identified a number of weaknesses impeding the conduct of maintenance activities at the Davis-Besse plant.1011 A subsequent NRC follow-up survey of the Davis-Besse maintenance activities in March 1986 indicated that the licensee had made considerable progress in all maintenance areas except maintenance backlog since the previous survey. Particular strengths noted were in the areas of maintenance training, spare parts, and material readiness. Based on the results of the March 1986 survey, the NRC concluded that the Davis-Besse new maintenance organization was functioning as planned, and no major identifiable weaknesses were evident. The few remaining problem areas noted by the staff were not considered programmatic weaknesses that would adversely affect the functioning of the maintenance organization.1011
In response to Issue 3 of the Commission Policy and Planning Guidance,210 the staff developed the MSPP that consisted of two phases: Phase I and Phase II. The findings of the Phase I activities were reported in NUREG-1212.1013 Essentially, the Phase I objectives (which were completed) addressed the objectives of this issue. In brief, Phase I of the MSPP was designed to survey existing maintenance practices in the nuclear utility industry, evaluate their effectiveness, and address the technical and regulatory issues of nuclear power plant maintenance.
Thirty-one measures of maintenance were developed for Phase I of the MSPP and organized into the following five categories: (1) overall system/component reliability; (2) overall safety system reliability; (3) challenges to safety systems; (4) radiological exposure; and (5) regulatory assessment. An analysis of the overall trends and patterns across the above five categories of maintenance revealed several important trends. In general, although plant maintenance performance showed some improvement from 1980 to 1985, the safety systems reliability for all plants did not significantly change since 1981. Thus, the contribution of maintenance to reliability problems indicated that some maintenance programs and practices were not effective. The Phase I findings confirmed that there were wide variations in maintenance practices among utilities and the industry had established a variety of programs aimed at self-improvement that did not appear to be well-integrated or effectively implemented in some cases. The resolution of the issues identified in Phase I of the MSPP were to be addressed in Phase II of the MSPP.
At the time of the initial evaluation of this issue in June 1987, the Phase II activities of the MSPP were being addressed in Issue HF8. In brief, Phase II of the MSPP required the staff to: (1) gather data to support a definition of the role of maintenance in safety; (2) develop goals for plant reliability in ensuring effective maintenance; (3) assess data to determine performance-oriented maintenance criteria; (4) make recommendations for endorsement of good maintenance practices; (5) recommend improvements to the maintenance/operations interface; (6) provide input to draft industry standards for maintenance; and (7) assess industry programs in self-improvement of maintenance programs.
CONCLUSION
The maintenance-related problems identified by the NRC IIT for the Davis-Besse plant were resolved.1011 For all operating plants, the objectives of this issue were essentially completed by Phase I of the existing MSPP. Phase II of the MSPP (Issue HF8) was expected to follow up and address problem issues identified in Phase I of the MSPP that warranted further NRC and industry actions.1013 Therefore, this issue was DROPPED from further pursuit as a new and separate issue.
ITEM 125.II.3: REVIEW STEAM/FEEDLINE BREAK MITIGATION SYSTEMS FOR SINGLE FAILURE
DESCRIPTION
Historical Background
During the investigation of the Davis-Besse event, the importance of the SFRCS became evident. Although the name of this system implies that its purpose is to mitigate steam and feedwater line breaks, in actual practice this is the AFW control system. Thus, the functions of this control system are more general than the name implies.
Safety Significance
Steam/feed line break mitigation systems vary in title and in detailed design from plant to plant and from vendor to vendor. However, they are generally composed of two logic trains in order to meet the single failure criterion. The presence of an unsuspected single failure would have the potential to greatly increase the probability of system failure. This has safety significance for several accident scenarios.
First, the reliability of mitigation of a steam or feedwater line break would be adversely affected. During such an event, the mitigation system isolates both the steam line and the feedwater (main and auxiliary) lines associated with the depressurizing steam generator. For most breaks outside containment, this stops the blowdown. For a break inside containment, the secondary side of the affected steam generator will blow down to the containment atmosphere, but isolation of feedwater to the affected steam generator will prevent continued long-term steaming due to decay heat from the reactor core. This is necessary to ensure that the containment design pressure is not exceeded.
This scenario was also the concern of Issue 125.II.7, "Reevaluate Provision to Automatically Isolate Feedwater from Steam Generator During a Line Break." The safety concern expressed here was not a duplication of Issue 125.II.7; rather, Issue 125.II.7 questioned the necessity of having this automatic isolation provision and thus was opposite in its thrust. Nevertheless, a detailed examination of the significance of this scenario was presented in the evaluation of Issue 125.II.7 and was not treated further here.
The second scenario was the loss of feedwater transient. If main feedwater is lost and not readily recoverable and a single failure in the AFW control system defeats AFW, most plants will have to use feed-and-bleed core cooling techniques to prevent core-melt. Because the viability of feed-and-bleed cooling is often questionable, and because non-recoverable loss of main feedwater events have in fact occurred many times, the reliability of the AFW system and its control system is of considerable importance. This was exactly the safety concern of Issue 125.II.1.b, "Review Existing AFW Systems for Single Failure." Thus, this safety concern was a duplicate of Issue 125.II.1.b.
The third scenario was specific to B&W plants. These plants provide AFW to the steam generators by means of a special AFW sparger. This sparger is located high in the steam generator and sprays water onto the steam generator tubes. The advantage of this arrangement is that it enhances natural convection through the primary system when forced circulation is lost. If a loss of forced circulation (i.e., trip of all 4 RCPs) transient were to occur and AFW were to fail, natural circulation might not provide sufficient core cooling to prevent cladding failure, even if some feedwater were being supplied to the secondary side of the steam generators. This was somewhat different from the safety concern of Issue 125.II.1.b, which was concerned with AFW reliability during loss of feedwater transients. Nevertheless, any upgrades brought about by the resolution of Issue 125.II.1.b was expected to address the loss of forced circulation concern as well. Therefore, this concern was also covered by Issue 125.II.1.b.
CONCLUSION
This issue had three aspects: (1) line break mitigation, which was covered in Issue 125.II.7; (2) loss of feedwater, which was covered in Issue 125.II.1.b; and (3) loss of forced circulation, which was also covered in Issue 125.11.1.b. Therefore, this issue was DROPPED from further pursuit as a new and separate issue.
ITEM 125.II.4: THERMAL STRESS OF OTSG COMPONENTS
DESCRIPTION
Historical Background
This issue addressed the effects of thermal stresses induced on the OTSG from a loss of feedwater transient and was based on RES concerns.941, 942
Safety Significance
The safety concern raised was that the introduction of the recovered feedwater to the dry OTSG, following the Davis-Besse transient, may have degraded the structural integrity of the OTSG and the steam generator tubes. The resulting transient-induced thermal stresses might lead to increased rupture frequencies for the steam generator components which, in turn, would increase the plant's core-melt frequency and the potential radiological risks to the public.
PRIORITY DETERMINATION
Following the Davis-Besse transient, the staff reviewed943 the B&W analysis regarding the possible effects of the transient to the structural integrity of the Davis-Besse OTSG. Comparisons were made between the Davis-Besse event and the B&W design basis analyses. Therefore, the conclusions reached below were considered applicable to similar transients of similar OTSGs (B&W) plants. This issue was not applicable to CE or W PWR plants that have U-Tube heat exchanger designs, and AFW injection that does not spray directly on the steam generator tubes.
The following components and/or events were considered to produce the most stress during transients involving boiled-dry OTSGs and subsequent recovery of auxiliary and main feedwater: (1) AFW nozzle; (2) main feedwater nozzle; (3) AFW jet impingement on steam generator tubes; (4) stresses on steam generator tubes due to steam generator shell/tube thermal stress; (5) degraded steam generator tubes; and (6) thermal shock of lower tube sheet.
AFW Nozzle: The stress and fatigue analyses of the AFW nozzle resulting from the Davis-Besse transient were compared to the original design basis temperature difference of 530F between the hot steam generator shell and the AFW injection temperature. During the transient, the temperature difference was 501F which was within the design basis analyses. The fatigue usage factor that was predicated on 875 AFW initiations, was also considered acceptable.943
Similar design basis analyses are conducted for all B&W OTSG designs except that the numbers of transients and nozzle designs are plant-specific.945 Therefore, the thermal stresses and fatigue component resulting from similar events were bounded by the original B&W design basis analyses.
Main Feedwater Nozzle: The original design basis stress analysis for the Davis-Besse OTSG was based on a temperature difference of 445F between the main feedwater nozzle and the feedwater. During the Davis-Besse transient, the temperature difference was approximately 162F.943 Therefore, the thermal stresses and fatigue factor resulting from the transient were considered bounded by the original B&W design basis. Similar design analyses are conducted for all B&W OTSG designs with the same exceptions as noted for the AFW nozzles.945
AFW Jet Impingement on Steam Generator Tubes: The original design basis assumed a temperature difference of 586F between the AFW coolant and the steam generator tube surfaces. Based on thermocouple data, the temperature difference between the steam generator tubes and the AFW was determined to be approximately 523F.943 Therefore, the thermal stresses and the fatigue factor (based on 29,400 cycles in the original Davis-Besse OTSG design basis) resulting from the transient were considered bounded by the original B&W design basis. Similar analyses (with the exception of the number of transients) were conducted for all B&W OTSGs.945
Steam Generator Shell/Tube Thermal Stress: Temperature differences between both steam generator shells and their tubes and the pressure differences across the tube sheets were analyzed based on thermocouple readings. The maximum temperature difference in one of the two steam generators was estimated to be approximately 72F. The resulting stresses and fatigue component were determined to be acceptable by the staff.943
Degraded Steam Generator Tubes: In NUREG-0565,96 the staff discussed its evaluation of B&W's analyses of potential defective steam generator tubes with up to 70% through-wall defects. The B&W thermal stress conditions included ten transients with maximum flaw orientations following a SBLOCA. The secondary side was postulated to have boiled dry and the primary system was significantly voided. The cold AFW impinging on the steam generator tubes and the pressure loads resulting from the tube-to-shell temperature differences, in combination with the potential effects of slug flow in the steam generator tubes from the voiding primary system, was evaluated. The staff concluded that the combination of conservative analyses and the test results provided assurance that structural integrity of the primary coolant pressure boundary (steam generator tubes) would be maintained.
Thermal Shock of Lower Tube Sheet: The stress and fatigue analyses relative to thermal shock of the lower tube sheet from the Davis-Besse transient were reviewed by the staff. The stresses and fatigue usage factor resulting from the transient were determined to be negligible. Therefore, it was concluded that the tube sheet was essentially unaffected by the Davis-Besse transient.943
CONCLUSION
The staff raised concerns relative to potential beyond design basis conditions that could increase the primary system temperatures above those previously analyzed. The higher superheat temperatures would lower the steam generator tube strength or, in combination with injected cold AFW temperature, might increase the thermal stresses. These conditions might then further degrade or fail the primary pressure boundary. At the time of the initial evaluation of this issue in September 1986, this potential phenomenon was being studied by the staff.944
The staff concluded that transients similar to the Davis-Besse transient were bounded by the original B&W design basis analyses. Therefore, the B&W OTSG design basis adequately accounted for such anticipated operational occurrences. Based on the staff findings, this issue involved no increase in risk to the public and was DROPPED from further pursuit as a new and separate issue.
The potential superheat phenomena being studied by the staff was beyond the existing design basis. Should the results of the superheat studies indicate a need for changes in the design basis of the primary and secondary pressure boundaries, it was recommended that any follow-up effort be evaluated as a new and separate issue.
ITEM 125.II.5: THERMAL-HYDRAULIC EFFECTS OF LOSS AND RESTORATION OF FEEDWATER ON PRIMARY SYSTEM COMPONENTS
DESCRIPTION
Historical Background
The Davis-Besse plant recovered feedwater flow following the loss of feedwater transient on June 9, 1985. With the loss of feedwater to the steam generators, heatup of the reactor coolant system peaked at about 592F and then, following recovery of the feedwater, decreased to 540F in approximately six minutes (normal post-trip average temperature is 550F). Thus, the reactor coolant system experienced an overcooling transient rate of 520F/hr for the 6-minute time interval.
Due to concerns identified,941, 942 the staff was requested940 to review and evaluate the safety significance of the thermal-hydraulic effects (potential pressurized thermal shock) to reactor pressure vessels, nozzles, and downcomer surface areas from such overcooling transients.
Safety Significance
The potential for pressurized thermal shock (PTS) to the reactor pressure vessel (RPV) and components from overcooling transients is more critical to PWRs by virtue of their designs. Therefore, this issue was applicable to all PWRs. With increased neutron radiation exposure, the temperature at which the RPV materials fracture toughness decreases to unacceptable limits increases. Thus, with time (neutron radiation exposure), the magnitude of the thermal stresses which are also compounded by pressure-induced stresses during overcooling transients, could approach reduced fracture toughness capabilities of the RPV materials.
Structural failure (fracture) of the RPV, to an extent that would make the RPV unable to contain sufficient water to cover the reactor core, would result in a core-melt. Given a core-melt and subsequent loss of containment integrity, public radiation exposure would result from the release of fission product materials.
Possible Solutions
For the Davis-Besse plant, the staff reviewed and evaluated the licensee's PTS calculations and results related to the June 9, 1985, event. Based on the staff's findings,1011 the temperature of the limiting weld in the Davis-Besse RPV would have had to drop an additional 377F to cause crack-initiation to become a significant PTS event.
To ensure that nuclear power plants do not operate with unacceptable PTS risks, the NRC promulgated a final rule1012 in July 1985 that amended its regulations to: (1) establish a screening criterion related to the fracture-resistance of PWR vessels; (2) require analyses and a schedule for implementation of neutron flux reduction programs to avoid exceeding the screening criterion; and (3) require detailed safety evaluations to be performed before plants commence operations beyond the screening criterion. The final PTS rule was a result of extensive analyses performed by the staff (Issue A-49, "Pressurized Thermal Shock") and several industry groups. The analyses covered all conceivable PTS events, including RPV overcooling transients, that were more severe than the Davis-Besse event.
CONCLUSION
The PTS concern from the Davis-Besse event was resolved in NUREG-1177.1011 All other conceivable PTS concerns were addressed in the resolution of Issue A-49 and the final PTS rule.1012 Therefore, this issue was DROPPED from further pursuit as a new and separate issue.
ITEMS 125.II.6: REEXAMINE PRA ESTIMATES OF CORE DAMAGE RISK FROM LOSS OF ALL FEEDWATER
DESCRIPTION
The memorandum that initiated this action recommended that plant-specific reliability data be solicited from Toledo Edison Company (the licensee for Davis-Besse).1004 This information would then be used by the NRC staff to formulate a new and revised model for estimating the frequency of severe accidents involving loss of main feedwater at the Davis-Besse plant. The purpose of this effort was to provide information, in addition to the results of deterministic reviews, to aid in decision-making concerning the restart of the Davis-Besse plant.
CONCLUSION
This task was a legitimate action on the Davis-Besse unit, but was not intended to address other plants since they were not in need of a restart decision. Therefore, the issue was not generic but was specific to one unit. However, before dismissing the issue, its generic potential was explored: What benefits would be reaped if other plants were investigated and modeled with plant-specific data?
At the time of the initial evaluation of the issue in March 1987, evaluations of plants with two-train AFW systems were being made in the resolution of Issue 124, "AFW System Reliability," and investigations along this line for all plants were also considered. In addition, Issue 125.II.1.b, "Review Existing AFW Systems for Single Failure," dealt with gathering of plant-specific information and Issue 125.II.1.c, "NUREG-0737 Reliability Improvements," dealt with specific AFW system reliabilities. Finally, Issue A-45, "Shutdown Decay Heat Removal Requirements," dealt with the question of plant safety for events (such as loss of all feedwater) where the plant's heat sink is lost. In view of the existence of all these issues, there was little to be gained by generalizing this new proposed action to form an additional generic task. As a result, this issue was DROPPED from further pursuit as a new and separate issue.
ITEM 125.II.7: REEVALUATE PROVISION TO AUTOMATICALLY ISOLATE FEEDWATER FROM STEAM GENERATOR DURING A LINE BREAK
DESCRIPTION
Historical Background
During the course of the investigation of the event, it was pointed out that the benefits of AFW isolation were probably more than outweighed by the negative aspects of this feature.940, 951
Safety Significance
The automatic isolation of AFW from a steam generator is provided to mitigate the consequences of a steam or feedwater line break. The isolation logic, usually triggered by a low steam generator pressure signal, closes all main steam isolation valves and also isolates AFW from the depressurizing steam generator. (The AFW flow is diverted to an intact steam generator.) The purposes of the AFW isolation are three-fold:
(1) The break blowdown is minimized. Shutting off AFW will not prevent the initial secondary side inventory from blowing down. However, the isolation will prevent continued steaming out of the break as decay heat continues to produce thermal energy.
(2) Overcooling of the primary system is reduced. As the depressurizing steam generator blows down to atmospheric pressure, the primary system is cooled down, causing primary coolant shrinkage and (if the event occurs near the end of the fuel cycle) a return to criticality, which adds a modest amount of thermal energy to the transient. Shutting off feedwater to the faulted steam generator will reduce this effect, although once again the initial blowdown will be the dominant factor.
The significance of these first two considerations is in containment pressure. The containment is designed to accommodate a primary system blowdown followed by decay heat boiloff (the large break LOCA). A steam or feedwater line break within containment might cause the containment design pressure to be exceeded if the AFW isolation were not present.
(3) The AFW isolation is needed to divert AFW flow to the intact steam generator(s). For the case of a two-loop plant with a two-train AFW system, this is needed to meet the single failure criterion in supplying feedwater to the intact steam generator. (The situation becomes more complex for other cases, e.g., a four-loop plant wlth a three-train AFW system.) Note that, unless the line break is in the AFW line, core cooling would still meet the single failure criterion even without the isolation, since the faulted steam generator would still be capable of heat transfer.
In summary, the automatic isolation is needed only to help mitigate a relatively rare event (steam or feedwater line break) and even then is only remotely connected with sequences leading to core-melt.
In contrast, this isolation has definite disadvantages. If both channels of the controlling system were to spontaneously actuate during normal operation, all AFW would be lost and the MSIVs would close. Most newer plants use turbine-driven main feedwater pumps. Thus, main feedwater would be lost also. If the plant operators fail to correctly diagnose and correct the problem, only feed-and-bleed cooling would be available to prevent core-melt. Similarly, if spurious AFW isolation were to occur during the course of another transient, once again only feed-and-bleed cooling would be available to prevent core-melt.
The long-term success of AFW for main feedwater transients, steam generator tube ruptures, and small LOCAs could also be compromised.951 During controlled cooldown, the thresholds for automatic AFW isolation are crossed. Procedures call for operators to lock out the isolation logic as the steam generator pressure approaches the isolation setpoint. Under these circumstances, the accompanying distractions make it possible that the operators will forget to override the AFW isolation logic in the permissive window. Thus, AFW reliability in these scenarios may be significantly degraded.
The safety significance of this issue arose from the fact that the negative aspects involve accident sequences which have more frequent initiators and more significant consequences than those of the positive aspects.
Possible Solution
A very straightforward solution was proposed: simply disconnect the AFW isolation valve actuators from the automatic logic and depend on plant procedures, i.e., have the operators close the AFW isolation valves (by remote manual operation from the control room) in the event of a line break.951 These procedures would require careful verification of the existence of a line break before isolating a steam generator from AFW.
PRIORITY DETERMINATION
Frequency Estimate
It was necessary to calculate estimates of both the positive and negative aspects of disabling the automatic AFW isolation. The positive aspects are due to a decrease in the frequency of loss of all feedwater events. There are three accident sequences of interest:
(1) The first sequence is initiated by a spontaneous actuation of both channels of the isolation logic. A two-loop plant design was assumed. There were no data readily available for such actuations; however, it was possible to make an educated guess. EPRI NP-2230307 provided some perspective, based upon actual experience with other systems:
|
Based upon these figures, it was expected that spontaneous actuations would occur with a frequency on the order of 0.03/RY. Of course, this would isolate only one steam generator. However, such systems generally have a common mode failure probability on the order of 5%. (In addition, the second train of AFW has an unavailability due to other causes of roughly 1%. However, the main feedwater system would still be available in this case.) Thus, the frequency of both steam generators isolating was (0.03/RY)(0.05) or 1.5 x 10-3/RY. Of course, the plant operators are likely to reset the logic and turn the transient around. A 1% (minimum) failure probability for recovery by operator action was assumed. This left feed-and-bleed cooling for which a typical failure probability of 0.20 and a maximum failure probability of 0.60 were assigned, based on the calculations presented in Issue 125.II.9, "Enhanced Feed-and-Bleed Capability." Multiplying these figures produced a core-melt frequency of 3 x 10-6/RY typical and 9 x 10-6/RY maximum.
(2) The second sequence is initiated by another, independent transient. During the course of this transient, and the consequent perturbation of a great many plant systems, the AFW isolation logic is triggered. The MSIVs close, causing a loss of main feedwater (if main feedwater has not previously been lost), and the AFW isolates. Again, unless the AFW isolation valves are reopened, only feed-and-bleed is available as a means of core cooling.
The AFW isolation logic can be triggered during a transient in two ways. The first is by some type of inadvertent systems interaction, e.g., electromagnetic coupling. The proper fix for this problem is to eliminate the systems interaction which may well have other consequences in addition to AFW isolation. Therefore, this effect was not considered here.
The second way to trigger AFW isolation is by the actual existence of low pressure in the secondary system, caused by the initiating transient. In this case, the isolation is working as designed (but not as intended). Low pressure transients are relatively rare, since the steam space in question is usually right on top of a significant quantity of water at saturation temperature. Low pressure will occur only if steam is vented at a rapid rate in sufficient quantity to cool the water inventory via boiloff to the point where saturation pressure drops below the AFW isolation setpoint. The other possibility is a dryout of the steam generator. This is possible for B&W plants because of the relatively low water inventory in the steam generators. However, such an event in a W or CE plant would probably imply that the main feedwater and AFW had already failed.
There was no readily available way of estimating the probability of a pressure drop, given a transient. However, EPRI NP-2230307 gave a frequency of 0.04/RY for events where PWR steam relief valves open. Thus, it was assumed that depressurization events occur with at least this frequency. Assuming further that 10% of these pressure drops are deep enough to trigger AFW isolation and that there is a 1% probability of failure of the operators to recover AFW, the resulting core-melt frequencies would be 8 x 10-6/RY typical and 2.4 x 10-5/RY maximum.
(3) The third sequence involved the long term success of AFW for main feedwater transients. During controlled cooldown, the thresholds for automatic AFW isolation are crossed. Procedures call for the operators to lock out the isolation logic as the steam generator pressure approaches the setpoint. If the operators fail to do so, both trains of AFW will isolate. Main feedwater is also unavailable, since its loss initiated the transient. Again, only feed-and-bleed would be available for core cooling.
Non-recoverable loss of main feedwater events are estimated to occur with a frequency of 0.64/RY.952 A 1% minimum probability of operator failure to bypass the isolation logic was assumed along with a 1% minimum probability of failure of the operators to recover the AFW system. In addition, there is still feed-and-bleed cooling which, because the plant is already partially cooled down, should have a better than usual chance of succeeding. Therefore, the feed-and-bleed failure probability was assumed to be 10% instead of 20% or 60%. The result was a core-melt frequency of 6.4 x 10-6/RY.
The three sequences above add up to a "typical" core-melt frequency of 1.7 x 10-5 /RY and as much as 3.9 x 10-5/RY for a plant with marginal feed-and-bleed capability. The negative aspects of the proposed fix were then evaluated.
The first negative scenario is the feedwater line break. Here, a break in the feedwater line to one steam generator initiates the sequence. With the proposed fix, the line is not isolated and one train of AFW simply pumps water out of the break. If the operator fails to manually isolate the break, the remaining AFW train fails, and feed-and-bleed techniques fail, core-melt will result.
Steam and feedwater line breaks are estimated to occur at a combined rate of 10-3 /RY (see Issue A-22). Because steam lines are larger and not as subject to water hammer phenomena, the feedwater lines are expected to be more likely to break than the steam lines. Therefore, it was assumed that feedwater lines will break with a frequency of 9 x 10-4/RY, i.e., 90% of the total line break frequency.
The unaffected single train of AFW should have a failure probability on the order of 0.01 or less. Consistent with the positive scenario calculations, a 1% probability of operator failure to manually isolate the affected steam generator was assumed along with a 20% typical, 60% maximum feed-and-bleed failure probability. The product was a core-melt frequency of 1.8 x 10-8/RY typical and 5.4 x 10-8/RY maximum.
The remaining scenario is a steam line break which could involve the theoretical possibility of containment failure by overpressure but does not lead to core-melt. It was assumed that the frequency of a line break will be 10-3, as before, and that there will be a 10% probability that the line break is in the steam lines, as opposed to the feedwater line breaks of the previous scenario. Once again, the probability of the operator to fail to manually isolate was assumed to be 1%. The frequency of higher than expected containment pressure due to long-term steaming in the faulted steam generator was then 10-6/RY.
The change in core-melt frequency is the algebraic sum of the various scenarios:
| Scenario | Core-melt Averted/RY | |
|---|---|---|
| Typical | Maximum | |
| Spontaneous Actuation | 3.0 x 10-6 | 9.0 x 10-6 |
| Transient Initiated | 8.0 x 10-6 | 2.4 x 10-5 |
| Cooldown Initiated | 6.4 x 10-6 | 6.4 x 10-6 |
| Feedwater Line Break | -1.8 x 10-8 | -5.4 x 10-8 |
| Net change in Core-Melt Frequency | 1.7 x 10-5 | 3.9 x 10-5 |
The estimated reduction in core-melt frequency for all reactors was 3.5 x 10-4 /year.
Consequence Estimate
The core-melt sequences under consideration here involve a core-melt with no large breaks initially in the reactor coolant pressure boundary. The reactor was likely to be at high pressure (until the core melts through the lower vessel head) with a steady discharge of steam and gases through the PORV(s). These are conditions likely to produce significant H2 generation and combustion.
The Zion and Indian Point PRA studies used a 3% probability of containment failure due to H2 burn (the "gamma" failure). This example was followed and 3% was used, considering that specific containment designs could differ significantly from this figure. In addition, the containment could fail to isolate (the "beta" failure). Here, the Oconee PRA figure of 0.0053 was used. If the containment did not fail by isolation failure or H2 burn, it was assumed to fail by basemat melt-through (the "epsilon" failure).
Assuming a central midwest plain meteorology, a uniform population density of 340 persons/square-mile, a 50-mile radius, and no ingestion pathways, the consequences were:
| Failure Mode | Percent Probability | Release Category | Consequences (man-rem) |
|---|---|---|---|
| gamma | 3.0% | PWR-2 | 4.8 x 106 |
| beta | 0.5% | PWR-5 | 1.0 x 106 |
| epsilon | 96.5% | PWR-7 | 2.3 x 103 |
The "weighted-average" core-melt would have consequences of 1.5 x 105 man-rem/ event.
These calculations covered all PWRs with large, dry containments. They did not apply to ice condenser containments. Because of the low free volume in such containments, failures due to overpressure were more likely and the averaged consequences could be significantly greater. However, the staff was not aware of any ice condenser plant with an automatic AFW isolation that was affected by the issue.
The steam-line-break/containment-rupture scenario is different. The containment pressure is unlikely to exceed the design pressure by more than a few percent, if at all. In most cases, the containment is calculated to fail at 2 to 2.5 times its design pressure. Therefore, containment failure by overpressure is at most a very remote theoretical possibility. It was assumed that the overpressure failure probability could not be greater than 3%, the H2 burn figure (a highly conservative assumption). The only radioactive release would come from the containment atmosphere and any primary coolant leakage or discharge from the PORV(s). There were no consequence estimates for such an event. However, the consequences could be conservatively bounded by those of a PWR-8 event, which was a successfully mitigated LOCA with failure of the containment to isolate. The PWR-8 consequences were 7.5 x 104 man-rem. Thus, the steam line break event would have "average" consequences of at most (0.03)(7.5 x 104) man-rem, or 2,250 man-rem, and probably much less.
It was not known how many plants were affected by this issue. In many plants, the AFW isolation logic had provisions to prevent isolation of feedwater to more than one steam generator. Others might not even have had this isolation logic. It was assumed that about 25% of the PWRs would be affected by this issue. At the time of the initial evaluation of this issue in September 1986, there were 83 PWRs and, by spring 1987 (the earliest that this issue was likely to result in changes), the remaining collective calendar life was 2,571 RY. At a 75% utilization factor, this was 1,928 RY or about 23 operational years per reactor.
The net change in man-rem/RY was obtained by multiplying the change in core-melt frequency by 1.5 x 105 man-rem (average) per core-melt. Then, the steam line break scenario was subtracted. The consequences of the steam line break scenario (upper bound) were simply (10-6 overpressure/RY)[2250 (average) man-rem/ overpressure], or 2.3 x 10-3 man-rem/RY.
| Scenario | Change in man-rem/RY | |
|---|---|---|
| Typical | Maximum | |
| Core-melt Scenarios | 2.6 | 5.9 |
| Steam Line Break | 0.0023 | 0.0023 |
| Net change | 2.6 | 5.9 |
The estimated risk reduction was 140 man-rem/reactor (maximum) and 1,300 man-rem for all reactors.
Cost Estimate
The proposed fix for this issue was simply to remove some leads from some equipment, an action that was likely to be more than paid for by decreased maintenance and testing. Nevertheless, even a relaxation of requirements as this would require review of each affected plant's isolation logic, to be certain that the net effect was an increase in plant safety. In addition, TS and procedural changes, with their associated paperwork, would be necessary. Industry and NRC costs of $32,000/plant and $25,000/plant, respectively, were assumed, which were typical for a complicated and controversial TS change. Thus, the estimated total cost associated with the resolution of this issue was (0.25)(83)($0.057M), or $1.18M.
Value/Impact Assessment
Based on an estimated public risk reduction of 1,300 man-rem and a cost of $1.18M for a possible solution, the value/impact score was given by:
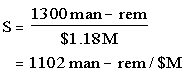
Other Considerations
(1) It should be noted that the maximum values were based upon a plant with marginal feed-and-bleed capability. The subset of PWRs that were affected by this issue may not have included such a plant. Thus, the "maximum" plant may not exist.
(2) The proposed fix did not involve work within radiation fields and thus did not involve ORE. However, the ORE averted due to post feed-and-bleed cleanup and post-core-melt cleanup was a consideration. In NUREG/CR-2800,64 the ORE associated with cleanup was estimated to be about 1,800 man-rem after a primary coolant spill and about 20,000 man-rem after a core-melt accident. The "typical" frequency of feed-and-bleed events was simply the "typical" core-melt frequency (1.8 x 10-5/RY) divided by the feed-and-bleed failure probability (0.20). The actuarial figures were:
| Averted Feed-and-Bleed Cleanup ORE/plant | 3.6 man-rem |
| Averted Core-melt Cleanup ORE/plant | 7.9 man-rem |
| Total: | 11.5 man-rem |
The total averted ORE for all plants was 240 man-rem. Thus, the averted ORE was not dominant, but was still a significant fraction of the averted public risk.
(3) The proposed fix would reduce core-melt frequency and the frequency of feed-and-bleed events and, therefore, avert cleanup costs and replacement power costs. The cost of a feed-and-bleed usage is dominated by roughly 6 months of replacement power while the cleanup is in progress. If the average frequency of such events was (1.7 x 10-5/0.20)/RY, or 8.5 x 10-5/RY, and the average remaining life was 23 operational years at 75% utilization, then assuming a 5% annual discount rate and replacement power costs of $300,000/day, the actuarial savings for feed-and-bleed cleanup was estimated to be $55,000. Similarly, the actuarial savings of averted core-melt cleanup (which was assumed to cost $1 billion if it were to happen) were about $200,000. The actuarial savings from replacement power after a core-melt, up to the end of the plant life, would be about $260,000. (This last figure represented the lost capital investment in the plant.) Obviously, these savings would more than offset the cost of the fix if they were included.
(4) The analysis of the first negative scenario, the feedwater line break, assumed that non-isolation of the ruptured line would cause one AFW train to fail. A special situation can arise for plants with a limited AFW water supply (e.g., saltwater plants). In such a case, the continued loss of clean water out of the feedwater line break can in theory cause failure of the second AFW train by exhausting the water supply, provided that the loss is not terminated either by the operator or by protective trips (for runout protection) on the first AFW train. In such a case, the scenario's negative contribution (typical) to the averted core-melt frequency of the proposed fix would rise from -1.8 x 10-8/RY to -1.8 x 10-6/RY. The net change in core-melt frequency would then drop from 1.7 x 10-5/RY to 1.6 x 10-5 /RY, which would not change the conclusion.
CONCLUSION
Based on the above analysis, particularly the core-melt frequencies, this issue was placed in the high priority category (see Appendix C). A regulatory analysis of the AFW automatic isolation feature showed that, for the postulated removal of the AFW automatic isolation feature in the plants analyzed, (a) the reduction in CDF would be about 10-7 core damage event/RY, and (b) the risk reduction would be about 40 man-rem/plant. Furthermore, for some plants, it was expected that removal of the automatic isolation of the AFW system would result in an increase in risk. This risk increase was particularly applicable to plants with no flow restrictors in the AFW pump discharge lines. The regulatory analysis was published as NUREG-13321133 in September 1988.
Based on the regulatory analysis and its supporting documentation, the staff concluded that removal of the AFW automatic isolation feature would neither result in a substantial safety improvement nor would it be cost-effective. Hence, Alternative Resolution No. 1 - "No Action," as recommended in NUREG-1332,1133 was adopted as the appropriate resolution of this issue in accordance with the Backfit Rule, 10 CFR 50.109(a)(3). Consistent with the SRP,11 the "No Action" alternative did not preclude a licensee from proposing to the NRC the removal of the AFW automatic isolation feature, based on plant-specific considerations. Thus, this item was RESOLVED and no new requirements were established.1134
ITEM 125.II.8: REASSESS CRITERIA FOR FEED-AND BLEED INITIATION
DESCRIPTION
Historical Background
During the course of the investigation of the Davis-Besse event,940 it was discovered that the EOP criteria for initiation of feed-and-bleed cooling were inadequate. The procedures directed the plant operators to initiate feed-and-bleed either if steam generator levels were below 8 inches on the startup range, or if the steam generator secondary pressures were less than 960 psig and decreasing. The difficulties with these criteria were: (1) the control room instrumentation was inadequate for the operators to determine that levels were below 8 inches; and (2) there was calculational evidence that steam generator secondary pressures were unlikely to fall below 960 psig before the opportunity for successful feed-and-bleed cooling was past.1002 Licensees were supplied with feed-and-bleed procedures by NSSS vendors.
Safety Significance
At the time of the initial evaluation of this issue in March 1987, feed-and-bleed capabilities were not required by the NRC, although the techniques, benefits, and costs were being evaluated in the resolution of Issue A-45. Basically, feed-and-bleed cooling is a method of last resort which can avert core damage if main and auxiliary feedwater are lost and other methods of decay heat removal are unavailable. PRAs take considerable credit for feed-and-bleed cooling. A failure rate of one or two percent is a typical assumption. However, the Davis-Besse event chronology left an impression that this failure probability may have been overly optimistic.
Possible Solution
The Davis-Besse EOPs were changed to a single criterion for initiating feed-and-bleed which stated that feed-and-bleed will be initiated if the primary coolant hot leg temperature rises above 610F. This parameter was expected to be much easier to monitor with existing control room instrumentation and, therefore, the new criterion was much clearer and unambiguous. The purpose of this proposed generic action was to confirm that all of the remaining B&W plants were using the new criterion rather than the two old criteria.1002
CONCLUSION
The safety concern and possible solution of this issue were covered in Issue 122.2, "Initiating Feed-and-Bleed." Issue 122.2 was one of the short-term Davis-Besse issues and was somewhat more general in that it was also concerned with the reluctance of the operators to initiate feed-and-bleed (because of the economic consequences), in addition to being concerned with inadequacy of the criteria.885, 887, 940 The two were related; less ambiguity in the written procedures implied less opportunity for reluctance to affect operator actions. Thus, this issue was DROPPED from further pursuit as a new and separate issue.
ITEM 125.II.9: ENHANCED FEED-AND-BLEED CAPABILITY
DESCRIPTION
Historical Background
This particular issue arose because of the very limited capability of the Davis-Besse plant to remove decay heat using feed-and-bleed techniques.940 Davis-Besse had a relatively low capacity PORV on the pressurizer and thus limited "bleed" capability. In addition, the HPI pumps (a part of the ECCS) did not develop sufficient discharge pressure to provide injection at operating pressure. To supply coolant at elevated pressure, the plant operators would have had to "piggyback" the makeup pumps on the HPI discharge, a complex procedure which would have supplied only rather limited flow. Thus, the "feed" capability was also limited. The issue was divided into two parts: Part A dealt with pressure relief capacity (i.e., enhanced "bleed" capability); and Part B dealt with makeup capacity and pressure (i.e., enhanced "feed" capability).
Safety Significance
Feed-and-bleed cooling is normally considered a method of last resort which can avert core damage if main and auxiliary feedwater are lost and not recovered. Nevertheless, main and auxiliary feedwater did both fail (but were recovered) at Davis-Besse and so the need for feed-and-bleed, although remote, was a possibility.
Feed-and-bleed cooling has the advantage of being a redundant and diverse method of core cooling. Its disadvantage (in addition to the economic consequences of releasing primary coolant to the containment) is that the plants were not designed for this mode of core cooling and thus their capabilities are uncertain.
An upgrading of the feed-and-bleed capability would benefit the viability of feed-and-bleed cooling in several ways: (1) the probability of failure due to component failure would be reduced (Feed-and-bleed cooling can fail due to a single failure at most plants.); (2) the thermal-hydraulic uncertainty would be reduced (Feed-and-bleed cooling is often only marginally viable. A slight change in the thermal-hydraulic initial or dynamic conditions could well prevent adequate core cooling.); (3) the "window" or time interval during which feed-and-bleed is viable would be lengthened, giving more time to (and less stress upon) the operating crew; and (4) the procedures for initiating feed-and-bleed would be simpler, thus reducing the probability of operator error.
Possible Solutions
The possible solutions to this issue were implicit in the definitions of the two parts: (1) increased pressure relief capacity; and (2) increased makeup capacity and pressure. Increased relief capacity could be accomplished by installing larger PORVs, installing more PORVs, or installing a special valve intended for bleed operations. Increased makeup capacity would involve upgrading or replacing the pumps (and their motors) with pumps of higher discharge pressure.
PRIORITY DETERMINATION
Frequency Estimate
To estimate changes in core-melt frequency due to the upgrades in pressure relief and makeup capacities, it was first necessary to calculate the change in failure probability of feed-and-bleed cooling. Prior to the initial evaluation of this issue in August 1986, the usual assumptions were either that the feed-and-bleed failure probability was dominated by the human failure mode (in NRC-generated PRAs), or that it was governed only by a few hardware failure probabilities (in industry-generated PRAs). Obviously, there was an inconsistency. Moreover, the issue to be addressed here affected both hardware and human failure rates. It was necessary to introduce a (somewhat) more sophisticated treatment of the problem. To do this, four classes of plants were defined.
Class 1: In this class, the plant's HPI pumps develop sufficient discharge pressure to lift the pressurizer safety valves. For such plants, feed-and-bleed cooling does not need the PORVs. Moreover, the HPI pumps are capable of raising the coolant level at any time right up to the point of core uncovery. There is no time interval "window" phenomenon.
Class 2: In this class, the plant's HPI pumps and/or charging pumps can force sufficient coolant in at operating pressure, but cannot lift the safety valves. Here, both PORVs must open for feed-and-bleed cooling to work. In addition, the viability of feed-and-bleed techniques is limited in time. Once the steam generators dry out, primary system pressure rises as the primary coolant heats up and expands. The PORVs will open and help keep pressure down, but eventually the pressure will rise up to the safety valve setpoint, by which time the HPI can no longer force coolant into the primary system. Thus, there is a definite "window" of time, pressure, and temperature during which feed-and-bleed cooling will work.
Class 3: In this class, the HPI pumps and/or charging pumps cannot force sufficient coolant into the primary system at operating pressure. Such plants must open the PORVs and reduce pressure to below normal in order to force sufficient coolant in. Of course, the timing is still more critical for such plants. Once the steam generators dry out, the PORV capacity will soon be overcome by primary coolant expansion and heating.
Class 4: This class is similar to Class 3 except that the PORV or PORVs are small. Such plants cannot sufficiently depressurize using PORVs after the steam generators dry out, but instead must open the PORVs and depressurize while the steam generators are still removing decay heat. In some cases, calculations have shown that the PORVs must be opened within 5 to 10 minutes after the beginning of the transient for core cooling to be successful.
It must be emphasized that real plants may not be easily classified into four neat classes. Nevertheless, these four classes will enable the benefits of enhanced feed-and-bleed to be scoped out. The benefit of enhanced pressure relief capacity can be shown by comparing Class 4 with Class 3, and the benefit of enhanced makeup can be shown by comparing Classes 2, 3 and 4 with Class 1. Given the four classes of plants, it was necessary to discuss the sources of failure for feed-and-bleed. These may be grouped into equipment, thermal-hydraulic, and human failure probabilities.
For feed-and-bleed to work, there must be both feed-and-bleed capabilities. Thus, a source of coolant at sufficient flow and pressure is necessary. This can be supplied either by the "charging" or "makeup" system (if of sufficient flow capacity) or by the HPI system (if of sufficient discharge pressure). In either case, the supply will generally be from a two-train system. Such systems generally have a failure probability of 1%.
Class 1 plants will discharge through the safety valves which have a failure probability of essentially zero. The other three classes must use (usually two) PORVs for coolant discharge. Each PORV has a probability of failure to open of 1%.54 When used for feed-and-bleed, these valves are not redundant; both must open.
Thermal-hydraulic effects are reasonably straightforward. For Class 1 plants, the thermal-hydraulic failure probability is essentially zero, since the high head HPI pumps will raise coolant level at any time. For Class 2 and Class 3, two time intervals were defined. The first is T1, which runs from the beginning of the transient up to the point of steam generator dryout. The second is T2, which starts at steam generator dryout and ends at the point of no return, when feed-and-bleed will no longer work. During interval T1, the initial conditions for feed-and-bleed onset are reasonably stable and there is high confidence that feed-and-bleed will work as planned. Thus, the probability of failure due to thermal-hydraulic effects was assumed to be zero during T1. During the second interval T2, the dynamic behavior of the reactor coolant system is much more complicated. In addition, the course of the transient may be significantly affected by a number of factors such as RCP operations, PORV cycling, pressurizer sprays, etc. Based primarily on judgment, the probability of failure was estimated to be 50% during this interval.
For Class 4 plants, the point of no return comes well before steam generator dryout. Thus, it was assumed that the probability of failure due to thermal-hydraulic effects was essentially zero for the first 10 minutes and unity thereafter.
Finally, accounting for human error was divided into three parts:
(1) Simple Procedural Error: Assuming a decision has been made to go ahead with feed-and-bleed and also that all equipment is operable, there is still a finite probability that the operator will make a mistake in initiating, monitoring, and controlling the process. This failure probability would be lowest for Class 1 plants since the operator need only initiate HPI and watch. A failure probability of 1% was assumed for this class. For Class 2, the initiation and control of feed-and-bleed are more complicated and a probability of 5% was assumed for interval T1. For Class 2 interval T2 and for Classes 3 and 4, the operator must depressurize first and then feed, being careful to keep pressure low enough to get adequate injection flow but high enough to avoid bulk boiling in the core (if possible). For this situation, a 10% failure rate was assumed.
(2) Time Stress: For this, Swain's screening model339 was used. The Class 2 and Class 3 interval T1 ends roughly 25 minutes into the transient, for which the screening model estimated a stress failure rate of about 3%. For the case of Class 4, where the point of no return is 10 minutes after the start of the transient, the screening model predicted a 50% failure probability. All the other classes and intervals were well over half an hour and the time stress failure rate was essentially zero.
(3) Simple Reluctance: The use of feed-and-bleed will release primary coolant to the containment atmosphere, contaminating the containment and necessitating a long expensive shutdown for purposes of cleanup. Moreover, feed-and-bleed techniques cause a small LOCA and thus have safety implications. Quite naturally, the plant operators will delay the use of feed-and-bleed as long as possible in the hope of recovering either main or auxiliary feedwater. Thus, there is a finite probability that initiation of feed-and-bleed would be delayed into interval T2 (for Classes 2 and 3) or even past the point of no return. Once again, it was necessary to use judgment. A 5% probability that the operators will wait until after the point of no return was assumed. For Classes 1 and 4, this translated directly into a 5% failure probability. For Classes 2 and 3, it was assumed that there was a 5% chance that feed-and-bleed will be started before the point of no return but after the point of steam generator dryout. This could perhaps best be understood in terms of success probabilities: there is a 90% chance of initiation during interval T1, a 5% chance of initiation during interval T2, and a 5% chance of either no initiation or initiation after interval T2.
For feed-and-bleed to succeed, all the potential pitfalls discussed above must be successfully overcome. Thus, the probability of successful feed-and-bleed is obtained by multiplying the success probabilities (not the failure probabilities) of the various contributors listed above. This is summarized in Table 3.125-2.
For Classes 1 and 4, the failure probability was calculated by first multiplying the equipment, thermal-hydraulic, and operator success probabilities to obtain a net success probability. This success probability was then subtracted from unity to get a failure probability.
Classes 2 and 3 were more complicated. Within each time interval, the various success probabilities were multiplied to get a net success probability for the interval. The interval success probabilities were then subtracted from unity to get an interval failure probability (i.e., the probability of no feed-and-bleed during that interval). Both intervals must fail to feed and bleed for feed-and-bleed to not take place at all. Therefore, the failure probability for the plant class was the product of the two interval failure probabilities.
With feed-and-bleed failure probabilities available, the next step was to calculate the changes in core-melt frequencies from these numbers. This was relatively straightforward in that the dominant sequence is almost always a transient involving a non-recoverable loss of main feedwater coupled with a failure of the AFW system and a failure to cool the core by means of feed-and-bleed techniques.
Table 3.125-2
| Class | 1 | 2 | 3 | 4 | ||
|---|---|---|---|---|---|---|
| Interval | T1 | T2 | T1 | T2 | ||
| Success Probabilities: | ||||||
| HPI | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 |
| PORV | - | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 |
| Thermal-Hydraulic | 1.00 | 1.00 | 0.50 | 1.00 | 0.50 | 1.00 |
| Operator: Procedural | 0.99 | 0.95 | 0.90 | 0.90 | 0.90 | 0.90 |
| Operator: Time Stress | 1.00 | 0.97 | 1.00 | 0.97 | 1.00 | 0.50 |
| Operator: Reluctance | 0.95 | 0.90 | 0.05 | 0.90 | 0.05 | 0.95 |
| Interval Success Probability | 0.9311 | 0.8047 | 0.0218 | 0.7624 | 0.0218 | 0.4148 |
| Interval Failure Probability | 0.0689 | 0.1953 | 0.9782 | 0.2376 | 0.9782 | 0.5852 |
| Class Failure Probability | 0.0689 | 0.1910 | 0.2324 | 0.5852 | ||
For the initiating event frequency (non-recoverable loss of main feedwater), 0.64 event/RY was used, based upon the Oconee PRA done by Duke Power Co.889 This figure was based on fault tree analysis and should be reasonably representative of most main feedwater system designs.
For a three-train AFW system, a "typical" unavailability was 1.8 x 10-5/demand.894 The analogous figure for a two-train system was significantly higher. However, at the time this issue was being evaluated, there was an existing program that was attempting to upgrade all AFW systems to a point where the maximum unavailability would be 10-4/demand.947 Thus, 1.8 x 10-5 was considered to be an average unavailability and 10-4 the maximum.
Core-melt frequencies (F) were then estimated by taking the product of the transient frequency, the AFW unavailability, and the change in the feed-and-bleed failure probability.
Consequence Estimate
The accident sequence under consideration involved a core-melt with no large breaks initially in the reactor coolant pressure boundary. The reactor is likely to be at high pressure (until the core melts through the lower vessel head) with a steady discharge of steam and gases through the PORV(s). These are conditions likely to produce significant H2 generation and combustion. The Zion and Indian Point PRA studies used a 3% probability of containment failure due to H2 burn (the "gamma" failure). This example was followed and 3% was used, considering that specific containment designs could differ significantly from this figure.
| From Class | To Class | Change in Core-melt Frequency* | Reason | |
|---|---|---|---|---|
| Typical | Maximum | |||
| 2 | 1 | 1.4 x 10-6 | 7.8 x 10-6 | Enhanced makeup capacity |
| 3 | 1 | 1.9 x 10-6 | 1.1 x 10-5 | Enhanced makeup capacity |
| 4 | 3 | 4.1 x 10-6 | 2.3 x 10-5 | Enhanced relief capacity |
| 4 | 1 | 6.0 x 10-6 | 3.3 x 10-5 | Enhanced makeup and relief capacity |
* in units of core-melt/RY
In addition, the containment can fail to isolate (the "beta" failure). Here, the Oconee PRA889 figure of 0.0053 was used. If the containment does not fail by isolation failure or H2 burn, it was assumed to fail by basemat melt-through (the "epsilon" failure).
Assuming a central midwest plain meteorology, a uniform population density of 340 persons/square-mile, a 50-mile radius, and no ingestion pathways, the consequences were:
| Failure Mode | Percent Probability | Release Category | Consequences (man-rem) |
|---|---|---|---|
| gamma | 3.0% | PWR-2 | 4.8 x 106 |
| beta | 0.5% | PWR-5 | 1.0 x 106 |
| epsilon | 96.5% | PWR-7 | 2.3 x 103 |
The "weighted-average" core-melt would have consequences of 1.5 x 105 man-rem. These figures should cover all PWRs with large, dry containments. However, they do not apply to ice condenser containments. There was no up-to-date PRA available for such a plant. However, because of the low free volume in such a containment, failure due to overpressure is more likely and the average consequences may be significantly greater.
Cost Estimate
The core-melt calculations were such that cost considerations did not affect the priority ranking. Consequently, a quantitative cost analysis was not attempted. However, it should be noted that the fixes were not inexpensive. A new or upgraded high pressure pump was likely to cost between $2M and $5M per train installed. Replacement PORVs or an additional, dedicated depressurization valve would not be as expensive, but would probably require replacement discharge piping with stronger bracing. The quench tank might also require extensive modification.
Value/Impact Assessment
To make the value/impact assessment, it was necessary to estimate the number of plants in each of the four classes. The first statement to be made was that all B&W plants except Davis-Besse had injection pumps capable of lifting the pressurizer safety valves. Thus, these plants were already in Class 1 and were outside the scope of this issue. This left 71 PWR plants. The earliest implementation of fixes was not likely to occur before the spring refueling outages in 1988, at which time the plants would have a collective remaining life of about 2,240 RY. At a 75% utilization figure, this was about 23.7 years of operational life per plant. It was not clear how these 71 plants were distributed among Classes 2, 3 and 4. A plant-by-plant investigation was beyond the scope of this evaluation. Therefore, it was assumed that roughly one-third fell in each class: 24 in Class 2; 24 in Class 3; and 23 in Class 4. With this data, priority parameters were estimated.
| Parameter | Part (a), Enhanced Relief | Part (b), Enhanced Makeup | ||
|---|---|---|---|---|
| Plant Class | 4-3 | 2-1 | 3-1 | 4-1 |
| Number of Plants | 23 | 24 | 24 | 23 |
| F (average) | 4.1 x 10-6 | 1.4 x 10-6 | 1.9 x 10-6 | 6.0 x 10-6 |
| F (max) | 2.3 x 10-5 | 7.8 x 10-6 | 1.1 x 10-5 | 3.3 x 10-5 |
| Core-Melt/RY (max) | 2.3 x 10-5 | 3.3 x 10-5 | ||
| Man-rem/reactor (max) | 80 | 120 | ||
| Core-Melt/year (Total, all plants) | 9.4 x 10-5 | 2.2 x 10-4 | ||
| Man-rem (Total, all plants) | 330 | 770 | ||
Other Considerations
(1) Upgrading the makeup capability would involve work on pumps which are located outside of containment. This should not result in a significant amount of ORE. However, upgrading the relief capacity would involve work adjacent to the pressurizer which would have implications for occupational exposure. There was no readily available data upon which a direct estimate of this exposure could be based. However, it should be noted that pressurizer inservice inspection involved roughly 20 man-rem and pressurizer spray valve repair involved roughly 10 man-rem. Thus, because the average (not maximum) plant would avert a public risk of about 15 man-rem, the ORE involved in the fix could be equal to or greater than the public exposure averted.
(2) In addition to ORE associated with the fix, there was averted ORE associated with cleanup of a core-melt. Core-melt cleanup exposure was assumed to be 20,000 man-rem. Using this and the core-melt frequencies calculated previously, the actuarial values (total, all plants) of averted core-melt cleanup ORE were about 45 man-rem for Part (a) and 100 man-rem for Part (b). On a per-plant basis, this was 2 man-rem/plant for both Parts (a) and (b) and was not a significant consideration.
(3) There were also averted costs associated with the issue. There would be no averted precursor events that involved major cleanup, but there would be averted cleanup costs associated with the reduction in core-melt frequency. In addition, averted core-melt implied averted replacement power costs for the remaining life of the plant. (Because the plant was built for the purpose of avoiding replacement power costs, this latter item represented the depreciated capital loss of the plant). Using the maximum core-melt frequencies above, a 31.5 calendar-year average remaining plant life, and the usual assumptions of $1 billion for core-melt cleanup, $300,000/day for replacement power, and a discount rate of 5%, the actuarial cost credits were:
| Part (a) | Part (b) | |
| Core-melt Cleanup | $270,000 | $390,000 |
| Averted Replacement | $350,000 | $510,000 |
| Power Costs | _______ | _______ |
| Total: | $620,000 | $900,000 |
This was probably not sufficient to offset more than a fraction of the cost of the proposed figures.
(4) The estimates of feed-and-bleed failure probability were based upon a time window assumption. That is, after continuing decay heat production in the reactor core has caused primary system pressure to rise to a certain point, the HPI pumps can no longer force coolant into the primary system. In addition, the PORVs are then venting at capacity and thus the primary system cannot be depressurized. Therefore, feed-and-bleed was assumed to fail if initiated after such conditions are reached.
However, a second opportunity for successful feed-and-bleed may exist. This would occur after the primary coolant boils away to the point where the core is starting to uncover. The steaming rate then begins to diminish and the PORVs may be able to depressurize the primary system to the point where the HPI pumps can reflood the core.
Of course, this depressurization is only possible because the decay heat is causing the uncovered fuel's temperature to rise instead of going into steam production. The pressure may not drop fast enough for core melt to be averted. Also, if the uncovered fuel slumps or crumbles and falls into the remaining liquid coolant, pressure will rise again. It was beyond the scope of this evaluation to address this (theoretical) second window possibility. However, any subsequent value/impact analyses should address the possibility of a second window.
(5) The analysis assumed a 1% failure probability for the PORV(s). Some plants had operated for extensive periods with the PORV block valves closed and electrically disabled. Restoration of power to the block valve operators, and subsequent opening of the block valves and PORVs to permit feed-and-bleed cooling, would take a significant amount of time as well as open new possibilities for equipment malfunction and operator error. Thus, such plants might have feed-and-bleed failure probabilities significantly greater than those calculated in the analysis above.
CONCLUSION
Based upon the above analysis, particularly the maximum core-melt frequencies, this issue would normally have been given a high priority ranking (see Appendix C). However, at the time the issue was being evaluated, feed-and-bleed techniques were being evaluated738 and were to be considered as one option in the resolution of Issue A-45.953 Therefore, this issue was DROPPED from further pursuit as a new and separate issue.
ITEM 125.II.10: HIERARCHY OF IMPROMPTU OPERATOR ACTIONS
DESCRIPTION
Historical Background
During the event, the operators did not initiate feed-and-bleed cooling immediately upon reaching plant conditions where feed-and-bleed operations were required by the emergency procedures.940 The feed-and-bleed method of cooling was delayed because of the operators' belief that recovery of feedwater was imminent and their reluctance to release reactor coolant to the containment structure. Even though feedwater flow was recovered before serious damage resulted, the event highlighted the need for establishing a hierarchy of actions in the procedures and/or training which would focus impromptu actions during an event to assure that decisions will be in the direction of safety, and not based on potential plant operational difficulties and financial impacts.
Safety Significance
Delays in implementing EOPs in a timely manner could defeat the design safety function of equipment and increase the severity of a transient or accident.
Possible Solution
Issue HF4.4 was expected to provide assurance that plant procedures are adequate and can be used effectively; the objective was to provide procedures that would guide the operators in maintaining the plant in a safe state under all operating conditions, including the ability to control upset conditions without first having to diagnose the specific initiating event. This objective was to be met by: (1) developing guidelines for preparing, and criteria for evaluating, EOPs, normal operating procedures, and other procedures that affect plant safety; and (2) upgrading procedures, training the operators in their use, and implementing the upgraded procedures.
In accordance with Appendix A of NUREG-0985, Revision 2,651 comparative studies were completed that examined the impact on operator performance in making the transition from procedure to procedure, using either event-based or function-oriented EOPs. At the time of the initial evaluation of this issue in February 1987, the results of these studies were being incorporated into a larger, ongoing project to develop guidance for achieving successful transitions with nuclear power plant operating procedures. DHFT/NRR concluded that, while the procedural guidance package could develop the correct guidance to place the reactor in a safe state, it might not prevent reluctance on the part of supervision or an operator to take action which will invariably result in a financial penalty. The TMI Action Plan Item I.B.1.3 (Loss of Safety Function) resolution to use existing enforcement options (citations, fines, and shutdowns) provided a deterrent to such actions, including willful violations that could effect the health and safety of the public (10 CFR 2, Appendix C). The Commission noted 234 that, while the procedures for enforcement actions might not ensure compliance, civil penalties and possibly criminal prosecution for willful violations were strong incentives to comply. NRC policy was that non-compliance should be more expensive than compliance. In cases involving individual operators licensed under 10 CFR Part 55, the Commission policy statement234 stated that, generally, licensees are held responsible for the acts of their employees. Accordingly, the NRC policy should not be construed as excusing personnel errors. Thus, enforcement actions involving individuals, including licensed operators, were to be determined on a case-by-case basis. The NRC policy was directed toward encouraging licensee initiatives for self-improvements and identification and correction of such problems.
CONCLUSION
The concern raised relative to reluctance of a licensee (or plant operators) to proceed with appropriate actions to place the plant in a safe state of operation, based on potential plant operational difficulties and financial impacts, was addressed by existing NRC policies.234 Based on the above discussion, the issue involving development of the hierarchy of impromptu operator actions was to be addressed in Issue HF4.4. Therefore, Issue 125.II.10 was DROPPED from further pursuit as a new and separate issue.
ITEM 125.II.11: RECOVERY OF MAIN FEEDWATER AS ALTERNATIVE TO AUXILIARY FEEDWATER
DESCRIPTION
Historical Background
The issue dealt with alternate means of recovering feedwater, should the AFW systems fail, and applied to all PWR plants.940
Safety Significance
Failure to provide feedwater makeup to the steam generators will cause them to boil dry in approximately 30 minutes or less. (This time varies for plant type and power level.) As steam generator water level decreases, heat removal rate is impaired and the temperature of the primary side increases. This leads to an imminent need to initiate feed-and-bleed cooling or find an alternate method of steam generator makeup. If no means of cooling is provided, the resulting loss of primary coolant inventory out of the pressurizer relief and safety valves will lead to core uncovery and meltdown.
Possible Solutions
In the resolution of Issue 124, "Auxiliary Feedwater System Reliability," the staff evaluated potential alternate recovery methods for both main and auxiliary feedwater systems for those (7) plants with two-train AFW systems. The staff effort was predicated on the lower AFW reliability associated with only two-train AFW systems, as opposed to the majority of plants that have three-train AFW systems. The staff evaluations consisted of plant-specific reviews and on-site audits.
As a more generic approach,1083 previous staff reviews of emergency procedure guidelines (EPGs) recognized that alternate methods to provide flow to the steam generator in the event of a loss of both main feedwater and AFW were desirable. Therefore, the EPGs for W and CE plants were revised to include instruction for an alternate means of feedwater recovery. A similar change was also required for inclusion in the B&W EPGs by Generic Letter No. 83-31.1085
CONCLUSION
The safety concern was addressed by the staff in Issue 124 and in revisions to EPGs. Therefore, the issue was DROPPED from further pursuit as a new and separate issue.
ITEM 125.II.12: ADEQUACY OF TRAINING REGARDING PORV OPERATION
DESCRIPTION
Historical Background
This issue affected all operating PWRs with PORVs in the primary coolant loop and called for an assessment of the adequacy of training regarding PORV operations.940 The issue stemmed from Findings 8 and 14 of the NRC investigation of the Davis-Besse event886 of June 9, 1985, in which the staff noted that the post-TMI improvements that focused on EOPs and training played a crucial role in mitigating the event.
Following actuation of the PORV during the event, the operator observed that the PORV open/close indicator showed that the PORV had closed. In fact, the PORV had not completely closed and, as a result, the reactor pressure decreased at a rapid rate for about 30 seconds. The operator, however, did not verify closure of the PORV by looking at the acoustical monitor installed after the TMI-2 accident; instead, he looked at the indicated pressure level which appeared steady. As a precautionary measure, the operator closed the PORV block valve. Fortunately, when the block valve was subsequently opened to assure PORV availability, the PORV had closed during the time the block valve was closed. Had the operator looked at the acoustical monitor, the need to close the block valve may have been factually confirmed and may have precluded the need for relying on the precautionary action taken. However, it should be noted that the operators had not generally placed high reliance on the acoustical monitors because of PORV leakage problems.
Safety Significance
Assessments of the adequacy of training and hands-on experience, referred to as performance-based training or Systems Approach to Training (SAT), was considered essential for providing assurance that nuclear power plants are operated in a safe state under all operating conditions. The adequacy of training regarding the PORV operation was part of the assessments of the performance-based training evaluations described in Issue 125.I.7.b, "Realistic Hands-on Training."
Possible Solution
A possible solution to this issue was to include an assessment of the adequacy of training regarding PORV operations in the job catalog of necessary tasks and functions required to safely operate and control nuclear power plant operations.
PRIORITY DETERMINATION
Frequency Estimate
PORV Challenge Frequency: The PORV challenge frequency was determined to be approximately 1/RY in Issue 70, "PORV and Block Valve Reliability."
PORV/Block Valve Failure Frequency: The frequency of failure of the PORV to close, given that it opened, was estimated to be 0.01/demand (see Issue 70). The frequency of failure of the block valve to function was estimated to be 0.003/demand (see Issue 70).
Operator Error Frequency: Based on the information in Issue 70, the human error probability (HEP) to close the PORV after the TMI Action Plan48 improvements and increased emphasis on operator training was estimated to be 0.05.
PORV-SBLOCA Frequency: The estimated base-case PORV/block-valve SBLOCA frequency (5.3 x 10-4/RY) was the product of the PORV challenge frequency (1), the probability that the PORV will stick open (0.01), and the probability that the operator will not close the PORV or the block valve fails to close (0.05 + 0.003).
To assess the potential improvement in HEP for PORV operations that could result from adequate hands-on training in upgraded simulators, a 30% reduction in HEP was assumed. (See Issue I.A.4.2, "Long-Term Training Simulator Upgrade.") Adjusting the above HEP = 0.05 to account for the potential reduction in HEP, the adjusted HEP = (0.7)(0.05) = 0.035. The resulting potential reduction in PORV-SBLOCA frequency derived by requiring the PORV training in the job catalog (Issue HF3.1) was therefore estimated to be [(5.3 x 10-4)/RY - (1)(0.01)(0.035 + 0.003] = 2.5 x 10-4 /RY. Given the visibility of PORV training since the TMI-2 accident, the above 30% reduction in HEP may have overestimated the potential HEP benefit. However, the assumed 30% reduction was expected to bound the safety significance of the issue.
Consequence Estimate
Ratioing the above reduction in PORV-SBLOCA frequency (2.5 x 10-4/RY) to the PORV-SBLOCA frequency from Issue 70 (1.05 x 10-3/RY) and multiplying by the core-melt frequency from Issue 70 (4.2 x 10-6/RY) yielded the potential reduction in core-melt frequency of (0.24)(4.2 x 10-4/RY) = 10-6/RY. The public risk reduction was, therefore, (0.24)(31 man-rem/reactor) = 7.4 man-rem/ reactor (see Issue 70).
CONCLUSION
Issue HF3.1 evaluated the task selection process for training program content based on the relative importance of operator tasks and requirements. Tasks involving the use of PORVs for both feed-and-bleed cooling and for identification of potential LOCAs were included in the generic INPO task analysis listings for PWRs and in NUREG-1122,974 Item EK3.03, "Actions Contained in EOP for PZR Vapor Space Accident/LOCA." This event had one of the highest importance ratings (4.6 of 5.0) for PWRs and was included in both training and NRC exams. The high frequency of PORV challenges was to be addressed in Issue HF3.1. Therefore, Issue 125.II.12 was DROPPED further pursuit as a new and separate issue.
ITEM 125.II.13: OPERATOR JOB AIDS
DESCRIPTION
In a DHFT/NRR memorandum900 on September 19, 1985, it was suggested that an assessment be made of the availability of appropriate job aids to obviate operators having to rely heavily on memory in emergency or "crisis" conditions. In a DSRO/NRR memorandum1072 of June 12, 1986, it was requested that DHFT/NRR evaluate this issue for inclusion in the Human Factors Program Plan (HFPP), or perform an analysis of the issue to determine its priority.
Safety Significance
In the Davis-Besse occurrence, two operator-related problems were encountered that were involved in the sequence of events that transpired. The first problem occurred when the secondary side operator, anticipating the automatic trip of the SFRCS which would start the AFW system, elected to perform a manual trip. However, the operator selected and actuated the wrong pair of pushbuttons from a set of five pairs and, instead of initiating an SFRCS trip for low water in the steam generators, obtained a trip for low steam pressure. This action isolated both steam generators from the AFW system by closing the isolation valves. At about the same time, both AFW pump turbines tripped on overspeed. Recovery of AFW pumps due to the overspeed trips could not be accomplished by actions in the control room.
The second problem was encountered when two equipment operators were unable to reset the AFW pump turbine trip throttle valves and promptly restore feedwater delivery to the steam generators. Both equipment operators, while having a reasonable amount of nuclear power plant experience, had never previously performed the task of resetting, latching, and opening the turbine trip throttle valves, particularly under full operating pressure. One equipment operator had successfully reset and latched the No. 2 trip-throttle valve but, due to the high friction caused by large differential pressure across the valve gate, removed only the mechanical slack in the valve mechanism and did not open the valve. The other operator had latched but did not reset the No. 1 trip-throttle valve and had partially opened the valve, but was fearful of applying more torque to open the valve further. The turbine, as a result, was operating at its normal speed, which did not provide enough discharge pressure to inject water into the steam generator. It was not until the assistant shift supervisor came into the pump room that the operators knew that the trip-throttle valves were not opened enough. At about the same time, another, more experienced, equipment operator arrived with a valve wrench; using this tool, he successfully opened the No.2 valve then also reset and opened the No. 1 valve.
Possible Solution
It was conceivable that operator aids could have reduced the likelihood of the first operator error and decreased the time required for the equipment operators to open the turbine trip-throttle valves. "Operator aids" is a term that applied to a broad category of items that assist the operators, physically or mentally, in accomplishing their tasks. Operator aids could be markings or codings, tags, tools, or devices to physically assist the operator, the layout or arrangement of equipment items, and the equipment design features including provision for human interface. Examples of operator aids that could have assisted the control room and equipment operators included, but were not limited to, the following:
(a) The markings on the SFRCS pushbuttons could have described the results of actuation rather than the trip which they generate. For example, instead of low steam pressure trip, the inscription could read SG feedwater isolation; and instead of low water level trip, they could be labeled AF initiation.
(b) Since a valve wrench is required to open the trip-throttle valves under pressure, a valve wrench could be permanently stored in the AFW pump rooms for use in emergencies.
(c) Since there existed some confusion about resetting and latching the trip-throttle valves, linkage guidance or instructions could be depicted on the AFW pump room walls to guide the unfamiliar. The mechanical linkage could also have been color-coded or conspicuously marked.
Again, the preceding were only examples of operator aids and were not intended to be an exhaustive list of aids that could have enhanced the operators' actions in the Davis-Besse event. Other generic issues that were related to the safety concern of this issue included: 125.I.7.a, "Recovery of Failed Equipment"; 125.I.7.b, "Realistic Hands-on Training"; and 125.II.10, "Hierarchy of Impromptu Operator Actions."
CONCLUSION
There was no dispute that operator job aids could enhance an operator's ability to perform his task. However, any attempt to define what job aids were needed on a generic basis was very difficult. Even more difficult were efforts to quantify the risk reduction that could result from efforts to improve or provide absent job aids. Any attempt at quantification would be very arbitrary and without much justification. Operator job aids was not a solution that stood on its own merit, but was supportive of other human factors elements such as staffing, qualifications, and training. While the availability of operator job aids could enhance an operator's ability to accomplish his task, the absence of job aids would only reduce the reliability of human performance and would not necessarily imply operator failure.
The presence or absence of operator job aids is a factor that is considered in the job task analysis and upon which training requirements are established. Provisions were included in the INPO-managed training accreditation program to ensure that the feedback from operating events, such as the Davis-Besse event, are included in utility training programs. In addition, a portion of the operator job aids was to be addressed in the resolution of the man-machine interface Issue HF5.1, "Local Control Stations."
At the time of the initial evaluation of this issue in March 1988, the safety concern had been addressed by the INPO Training Accreditation Program, which was endorsed in March 1985 by the Commission Policy Statement on Training and Qualification of Nuclear Power Plant Personnel.996 Therefore, this issue was DROPPED from further pursuit as a new and separate issue.
ITEM 125.II.14: REMOTE OPERATION OF EQUIPMENT WHICH MUST NOW BE OPERATED LOCALLY
DESCRIPTION
Historical Background
During the course of the investigation of the Davis-Besse event, it was noted that a startup feedwater pump (SUFP), a part of the main feedwater system that would have been very helpful in the mitigation of the transient, had been intentionally disabled because of an NRC concern with high energy line breaks in the area of essential safety equipment and the ability of ECCS equipment to meet single failure criteria. Although the Davis-Besse event specifically involved a SUFP, it was intended that this issue cover all equipment that had been disabled such that it was no longer remotely operable from the control room.
Safety Significance
The significance of purposely disabled equipment was primarily in timing. Generally, it is possible to restore such equipment to an operable status. However, plant personnel must be dispatched to the equipment to perform local, manual operations such as unlocking and manipulating manual valves, restoring and closing breakers, etc. This can require considerable time and restoration to operability may well come too late to aid in accident mitigation. Moreover, the relatively complex procedures involved, done under emergency conditions, are prone to error. Finally, the nature of the incident may well be such that the disabled equipment is rendered inaccessible.
Possible Solution
The solution proposed900 was straightforward: "Review each piece of motor-operated equipment originally designed to be operated from the control room or other panel areas which has been disabled physically such that it can only be operated locally to determine whether such disabling truly is in the interest of overall plant safety."
PRIORITY DETERMINATION
Over the years prior to the event, there were many instances where equipment had been intentionally disabled. In the case of the Davis-Besse SUFP, the reason for disabling was to ensure that the discharge lines, which were not seismically qualified and which also are routed near essential safety equipment, could not rupture and disable this equipment. Other reasons also existed. For example, in the past, equipment was disabled by removal of breakers to permit older ECCS designs to meet the single failure criterion.
This issue was non-specific in the sense that it addressed any of the disabled equipment. Thus, re-enabling of this equipment may affect LOCA sequences, transient-initiated sequences, etc. Because of this very general nature, it was impossible to quantify all aspects explicitly. The approach used was to evaluate a SUFP similar to that of Davis-Besse, but (unlike the case of Davis-Besse) capable of providing sufficient flow by itself to permit decay heat removal by means of the steam generators. Because such a pump would help mitigate transient-initiated sequences, which are relatively frequent compared to (for example) LOCA-initiated sequences, this scenario provided an upper bound to the priority parameters.
Frequency Estimate
The sequence of interest was initiated by a non-recoverable loss of main feedwater. If the auxiliary feedwater system fails, the SUFP is not re-enabled in time, and feed-and-bleed techniques fail, core melt will ensue.
An initiating event frequency (non-recoverable loss of main feedwater) of 0.64 event/RY was used, based upon the Oconee PRA done by Duke Power Co.889 This figure was based upon fault tree analysis and was reasonably representative of most main feedwater system designs.
For a three-train AFW system, a "typical" unavailability was 1.8 x 10-5/demand.894 The analogous figure for a two-train system was significantly higher. However, at the time of the initial evaluation of this issue in August 1986, consideration was being given in Issue 124 to the upgrade of all AFW systems to a point where the maximum unavailability would be 10-4/demand. The affected plants would almost certainly upgrade their SUFPs (if present) to help meet this criterion, which made this issue moot for these plants; thus, an unavailability of 1.8 x 10-5/demand was used.
A typical value of 0.20 was assumed for the failure probability of feed-and-bleed cooling, based on the calculations presented in Issue 125.II.9, "Enhanced Feed-and-Bleed Capability."
The SUFP non-recovery probability remained to be calculated. According to the Investigation Team's report on the Davis-Besse event,886 restoration of the SUFP normally was expected to take 15 to 20 minutes. Nevertheless, the assistant shift supervisor managed to do it in roughly 4 minutes during the June 9, 1985, event. Obviously, not all plant personnel will go through the procedure as rapidly as the assistant shift supervisor at Davis-Besse, even given the extra motivation of a real event. It was assumed that the time needed to restore the SUFP to operability could be described by a normal distribution, centered at 17.5 minutes and with a width such that the assistant shift supervisor's performance of 4 minutes will be at the first 95 percentile point.
The time intervals above were measured from the start of the restoration procedure. It was desirable for calculational purposes to measure time from the initiation of the transient. Noting from NUREG-1154886 that the SUFP was restored at t = 16.38 minutes (measured from the start of the transient) after four minutes of rapid work on the part of the assistant shift supervisor, the significant times were:
| t | = 0, | start of transient |
| t | = 12.38 minutes, | start work on SUFP |
| t95 | = 16.38 minutes, | 95 percentile point |
| t0 | = 29.88 minutes, | mean time for restoration |
Thus, the probability of the SUFP being restored within the interval from t to (t + dt) was given by:
P(t)dt = (![]() 2
2
![]()
![]() ) exp{-½[(t-t)/
) exp{-½[(t-t)/
![]() ]}dt, where
]}dt, where
![]() = 8.93 minutes (based on t - t = 13.5 minutes)
= 8.93 minutes (based on t - t = 13.5 minutes)
If one is willing to wait long enough, the integrated probability of restoration will approach unity. However, there is a point in time after which restoration of the SUFP will no longer save the core. Although it was not clear just when this time would be, it was safe to assume that it would occur after steam generator dryout which is typically at least 25 minutes into the transient. The probability of no restoration was given by:
PF(T) = ![]() P(t) dt, where T 25 minutes
P(t) dt, where T 25 minutes
There was no closed form solution to this integral. However, standard statistical tables readily give an answer of PF(T) 0.29.
One last effect needed to be considered. Consistent with Issue 122.3, "Physical Security System Constraints," an additional 1% probability of the plant personnel being unable to reach the equipment location because of locked doors, etc., was considered. The core-melt frequency then became:
| Core-melt/RY | <(0.64 loss of main feedwater events/RY) x (1.8 x 10-5 AFW failure probability) x (0.20 feed-and-bleed failure probability) x (0.29 + 0.01 SUFP non-restoration probability) |
| <6.9 x 10-7 |
Consequence Estimate
The core-melt sequence under consideration involved a core-melt with no large breaks initially in the reactor coolant pressure boundary. The reactor is likely to be at high pressure (until the core melts through the lower vessel head) with a steady discharge of steam and gases through the PORV(s). These are conditions likely to produce significant H2 generation and combustion.
The Zion and Indian Point PRA studies used a 3% probability of containment failure due to H2 burn (the "gamma" failure). This example was followed and 3% was used, considering that specific containment designs could differ significantly from this figure. In addition, the containment can fail to isolate (the "beta" failure). Here, the Oconee PRA figure of 0.0053 was used. If the containment does not fail by isolation failure or H2 burn, it was assumed to fail by basemat melt-through (the "epsilon" failure).
Assuming a central midwest plain meteorology, a uniform population density of 340 persons/square-mile, a 50-mile radius, and no ingestion pathways, the consequences were tabulated below. The "weighted-average" core-melt would have consequences of 1.5 x 105 man-rem.
The plants to be examined included all 94 plants that were in operation as of August 1986. By the fall of 1987 (the earliest that changes were likely to be made), these plants were expected to have an aggregate remaining license life of 2,718 RY. This corresponded to an average life of 29 calendar-years/plant. At a 75% utilization factor, this was equivalent to 22 operational years/plant.
It was not known how many plants would be affected by this issue. It was assumed that at least a few plants would be found and the priority parameters were calculated on a per-plant basis. Thus, the estimated risk reduction was (6.9 x 10-7)(22)(1.5 x 105) man-rem/plant, or 2.3 man-rem/plant.
| Failure Mode | Percent Probability | Release Category | Consequences (man-rem) |
|---|---|---|---|
| gamma | 3.0% | PWR-2 | 4.8 x 106 |
| beta | 0.5% | PWR-5 | 1.0 x 106 |
| epsilon | 96.5% | PWR-7 | 2.3 x 103 |
Cost Estimate
Once equipment is identified, a detailed analysis would be required to verify if the disabling of the subject equipment is truly in the interest of plant safety. If the analysis indicated that the equipment should not be disabled, the original reason for disabling must still be addressed. (Alternatives to disabling may be necessary to address the original concern.)
The minimum cost would correspond to a case where the equipment is process equipment, which is fully maintained and needs only to have valves opened and breakers re-installed, which was assumed to take roughly 17.5 minutes of labor. If it also turns out that no other alternatives are necessary, the cost would be dominated by analysis and paperwork. It was estimated that probabilistic analyses would require approximately 10 weeks/plant of staff time (NRC and industry combined) at $100,000/staff-year. In addition, per-plant costs of $13,000 for NRC and $16,000 for a licensee would be incurred for a typical TS change. The minimum cost was then about $50,000/plant.
Value/Impact Assessment
Based on an estimated public risk reduction of 2.3 man-rem/reactor and a cost of $50,000/reactor for a possible solution, the value/impact score was given by:

Other Considerations
The aggregate parameters (total man-rem, all reactors, and total core-melt/year, all reactors) were not calculated. An examination of the scale factors for these parameters readily showed that at least 50 plants must be affected before it was possible for these parameters to be limiting.
In most cases, the fix would not involve work within radiation fields and thus would not involve ORE. The ORE averted due to post-feed-and-bleed-cleanup and post-core-melt cleanup was a minor consideration. The ORE associated with cleanup was estimated to be 1,800 man-rem, after a primary coolant spill, and 20,000 man-rem, after a core-melt accident.64 If the frequency of feed-and-bleed events was 3.46 x 10-6/RY, the actuarial cleanup ORE averted would be only 0.14 man-rem/reactor. Similarly, a core-melt frequency of 6.9 x 10-7/RY corresponded to an actuarial averted cleanup ORE of only 0.30 man-rem/reactor. If averted ORE were added to the man-rem/reactor and man-rem/$M calculations above, no conclusions would change.
The proposed fix would reduce core-melt frequency and the frequency of feed-and-bleed events and, therefore, would avert cleanup costs and replacement power costs. The cost of a feed-and-bleed usage will be dominated by roughly 6 months of replacement power while the cleanup is in progress. If the average frequency of such events was 3.46 x 10-6/RY and the average remaining plant life was 29 calendar-years at 75% utilization, then assuming a 5% annual discount rate and a replacement power cost of $300,000/day, the actuarial savings for feed-and-bleed cleanup was estimated to be $2,200. Similarly, the actuarial savings of averted core-melt cleanup (which was assumed to cost one billion dollars if it happens) were about $7,900. The actuarial savings from replacement power after a core-melt up to the end of the plant life would be about $9,600. (This last figure represented the lost capital investment in the plant.) If these theoretical cost savings were subtracted from the expense of the fix, the value/impact score would rise to 76 man-rem/$M and would not change any conclusions.
Some caution was needed in the use of the numbers calculated above since these were maximum numbers, calculated for a worst case scenario, and equipment has often been disabled for good reasons. Re-enabling such equipment would generally have drawbacks as well as benefits and the net effect on plant safety would not necessarily be positive.
CONCLUSION
Based on the above calculations, the issue was given a low priority ranking (see Appendix C). In NUREG/CR-5382,1563 it was concluded that consideration of a 20-year license renewal period did not change the priority of the issue. Further prioritization, using the conversion factor of $2,000/man-rem approved1689 by the Commission in September 1995, resulted in an impact/value ratio (R) of $21,739 /man-rem, which placed the issue in the DROP category.
REFERENCES
|